Notifications
Clear all
Topic starter
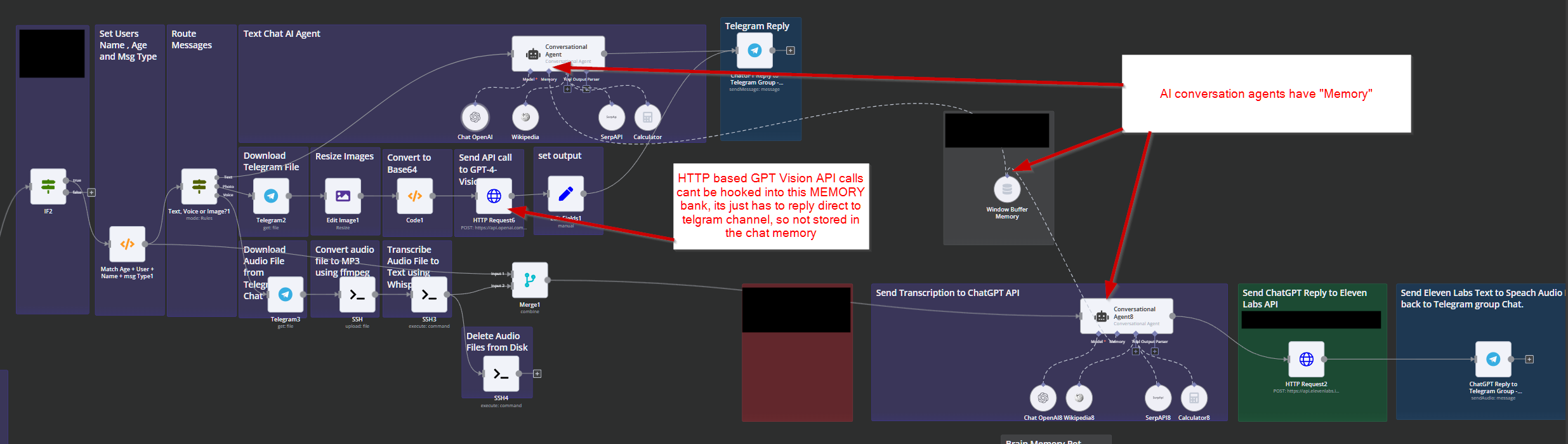
I'm utilizing conversational agents along with in-store memory to manage conversations, and it's functioning effectively. However, I encountered an issue when I attempted to integrate the OpenAI Vision API.
Currently, there's no direct method to enable vision capabilities by uploading a base64 encoded image or an image URL, which is necessary for OpenAI to process the image.
As a result, I have an HTTP node that makes an API call and receives a response. The problem is that I cannot add this response to the memory store because it did not originate from a conversational agent. If I attempt to feed the output from the HTTP node into the conversational agent, it tries to respond to itself, leading to a duplicated API usage for the same query.
There must be a way to incorporate this HTTP OpenAI Vision input into the conversational agents.
payload = {
"model": "gpt-4-vision-preview",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "What’s in this image?"
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
}
]
}
],
"max_tokens": 300
}
Posted : 26/01/2024 11:20 am
It appears your topic is missing some crucial details. Could you please provide the following information, if relevant?
- callin.io version:
- Database (default: SQLite):
- callin.io EXECUTIONS_PROCESS setting (default: own, main):
- Running callin.io via (Docker, npm, callin.io cloud, desktop app):
- Operating system:
Please provide the requested details.
Posted : 26/01/2024 11:20 am
Hi there,
I'm not entirely sure I grasp what you're aiming for. Are you looking to add the output from a standard node into a memory store for later use? Perhaps you're invoking your HTTP node as a tool within a different callin.io workflow?
Please clarify your objective.
Posted : 26/01/2024 1:08 pm
Topic starter
Perhaps this will be helpful?
HTTP GPT VISION API CALL
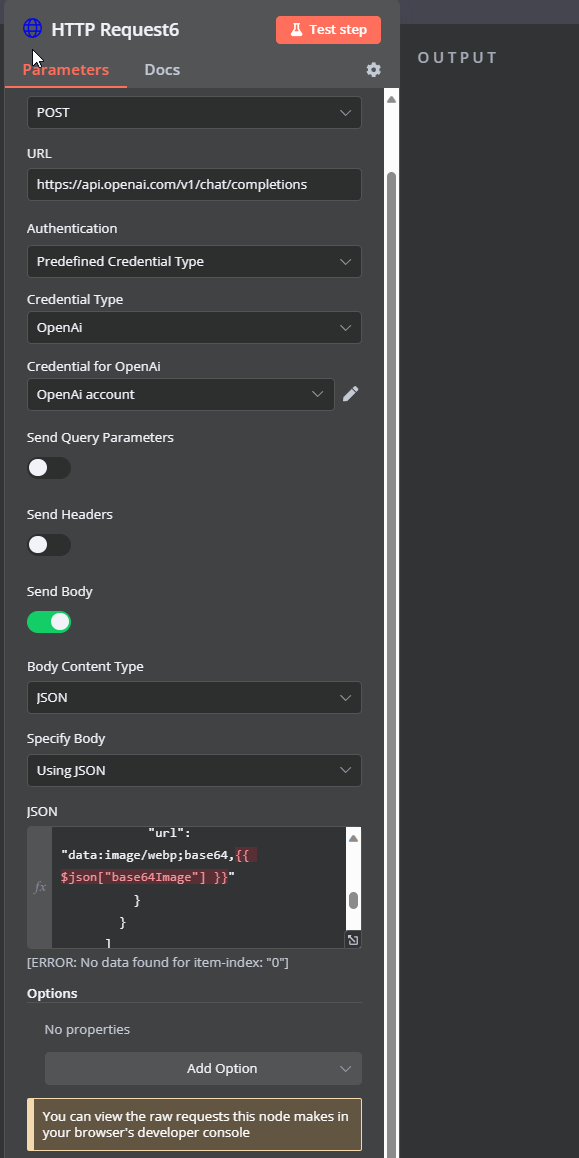
This is the payload, but it cannot be utilized within the conversational agent's inputs. Consequently, I must resort to using an HTTP node, despite the availability of a GPT vision option within the model settings for the AI agent.
{
"model": "gpt-4-vision-preview",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "What’s in this image? If it is food extract potential calories."
},
{
"type": "image_url",
"image_url": {
"url": "data:image/webp;base64,{{ $json["base64Image"] }}"
}
}
]
}
],
"max_tokens": 300
}
Does that clarify things a bit?
Posted : 26/01/2024 1:25 pm
This makes it more confusing. Since you are not going through the conversational agent, I wouldn't expect the memory to function.
What occurs if you utilize the output from the HTTP request node within the conversational agent as an input?
![]()
Alternatively, what happens if you place that HTTP request node in a workflow and then call it as a tool from the agent? Does that work?
Posted : 26/01/2024 1:48 pm
Topic starter
It
takes its output as input and attempts to formulate a response, which is not useful.
I will investigate the sub-workflow approach to see how it goes. This might serve as a temporary solution until the conversation agent is updated to support image inputs, etc.
Posted : 26/01/2024 1:52 pm
This discussion was automatically closed 90 days following the last response. New replies are no longer permitted.
Posted : 25/04/2024 1:53 pm