Notifications
Clear all
Topic starter
Struggling with your AI agent interrupting users during two-way conversations? This often happens because your agent doesn't distinguish between partial messages or pauses, failing to recognize when users have finished their turn. Turn detection is a technique to address this, with various approaches. In this article, I'll share an experiment on detecting the 'end of utterance' within callin.io.
Hey there
![]()
I’m Jim. If you've found this article helpful, please consider giving me a "like" and following me on callin.io or X/Twitter. For more content on similar topics, explore my other AI posts in the forum.
“Predicting End of Utterance” is a technique to reduce interruptions from AI voice agents. I came across this topic while listening to Tom Shapland’s talk at the AI Engineer World Fair 2025 on June 5th.
The core idea is to analyze recent message history to predict when a user has finished their message, which isn't always the same as when they pause. It sounds simple, but it was quite challenging to implement!
This prediction task typically uses traditional ML. I wanted to see how well an LLM would perform. Naturally, I built this in callin.io, as several of my chat agents could benefit. Despite the difficulties, I managed to create a working example to test the technique. My initial concern was performance, but it was surprisingly efficient and, in my opinion, a perfectly viable alternative to buffering user messages via timeout.
Good to know
While “Turn detection” usually refers to voice, this article's use case involves instant text messaging scenarios, such as through Telegram and WhatsApp. If you're interested in turn detection for audio, here are some resources:
- Turn detection and interruptions | LiveKit Docs
- GitHub - pipecat-ai/smart-turn - conveniently hosted on Fal.ai here Pipecat's Smart Turn model | Speech to Text | fal.ai
How it works

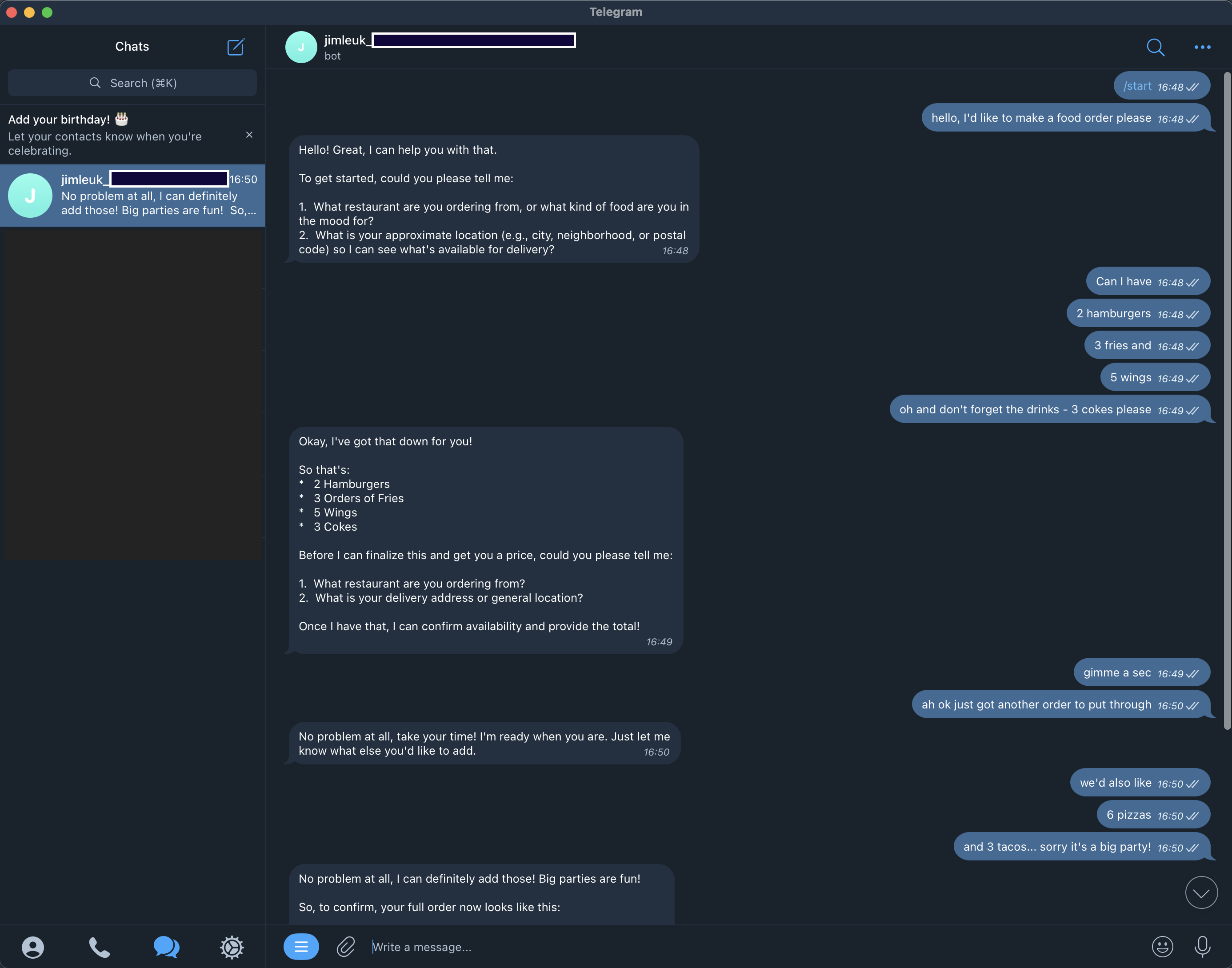
1. Chat Messaging with Async Responses (Telegram, Whatsapp)
Because we need to buffer messages, we require complete control over when the AI agent responds. This means the built-in callin.io chat trigger isn't suitable, as I don't believe there's a way to skip replying to user messages. However, this isn't a major issue if you're using Telegram or WhatsApp, as they work well with this technique.
2. Redis for Session Management
I chose Redis as my data store for buffering messages and managing conversation state. In my experience, Redis is exceptionally fast for handling and retrieving ephemeral data. Furthermore, Redis's automatic record expiration simplifies data management.
3. The Prediction Loop using callin.io’s Wait Functionality
The “prediction” step involves using an LLM to analyze buffered user messages and determine if the agent should send a reply. This analysis uses a text classifier with two outputs: true if the end of the turn is detected, or false if more input is expected.
The challenge with this type of workflow is avoiding inference on every execution, which could lead to duplicate replies and out-of-sync turn states if predictions run in parallel.
My solution was to implement a single loop that only starts when a new user message is received. If the prediction is false, it waits for more buffered messages before looping back to try the prediction again. I used callin.io’s wait node to implement this waiting mechanism.
The key is the “waiting” itself. Instead of being time-based, the wait node is set to resume via webhook. This requires an HTTP request to the execution's resumeURL to continue. When new messages arrive and a prediction loop is already active, the message is buffered and triggers the resumeURL instead of starting a new prediction. This action prompts the waiting execution to resume, thereby continuing the prediction process.
The Template
I’m happy to share my turn detection template for Telegram on my creator page.
Check it out and let me know if you test it – I’d appreciate your feedback for improvements! Feel free to substitute Telegram or Redis with your preferred tools.
Conclusion
-
Turn detection appears to be a more sophisticated solution. It noticeably reduces interruptions, and as a user, I feel less pressure to respond quickly. When I'm finished, the agent replies with minimal delay, creating a more natural and real-time conversation.
-
Using LLMs for turn detection is indeed feasible! I believe there's room for improvement, as I likely didn't use the most optimal prompt or the fastest model for the prediction task.
Do you know of other turn detection methods or approaches? Please share them in the comments below, and I'll review and compare them. Thanks! .
If you've found this article helpful, please consider giving me a "like" and following me on callin.io or X/Twitter. For more similar topics, check out my other AI posts in the forum.
Still not signed up for callin.io cloud? Support me by using my callin.io affiliate link.
Need more AI templates? Check out my Creator Hub for more free callin.io x AI templates – you can import these directly into your instance!
Posted : 21/06/2025 4:21 pm