Notifications
Clear all
Topic starter
Describe the problem/error/question
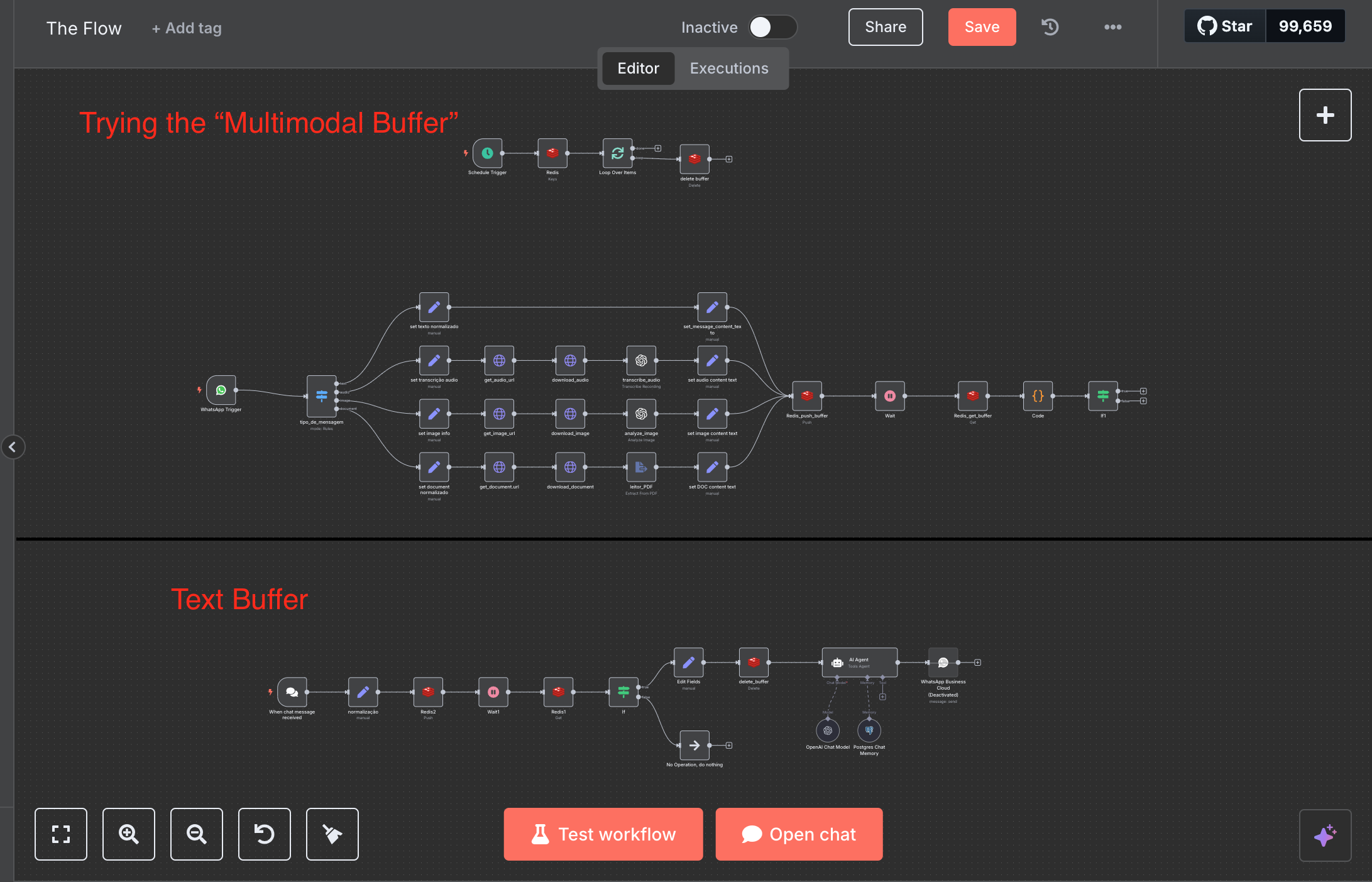
I’m developing a multimodal AI assistant using callin.io that handles fragmented messages from WhatsApp (text, audio, image, PDF). My objective is to aggregate these messages using Redis for consolidated processing after the user has finished sending them.
The aim is to create a smart buffer where each input is temporarily stored. After a brief pause (approximately 6 seconds), all collected parts are retrieved, parsed, merged, and then sent to OpenAI GPT-4o for response generation.
I'm utilizing the Redis node (via Upstash) to Push each message (formatted as JSON.stringify($json)), and subsequently Get them back to reconstruct the conversation context.
No error message, but I'm struggling to find a solution, and the JSONs don't match in the conditional node.
I want to create a humanized AI agent for a medical clinic.
One of the most crucial insights from developing conversational AI systems is that users seldom convey all their intentions in a single message.
Particularly on platforms like WhatsApp, it's common for users to break up their thoughts. They might start with a brief text, follow up with a voice note, and then add an image or even a PDF. This reflects natural human communication patterns. However, most automation workflows and AI integrations are designed to react instantly to each incoming message, without waiting or verifying if further input is forthcoming.
This approach results in superficial responses, a lack of context, and a subpar user experience.
To address this, I've implemented a buffering mechanism that monitors various media types. When a user sends any input—be it text, audio, image, or document—it's processed into plain text and temporarily stored. A short waiting period (around 6 seconds) allows the user to fully express their thoughts. Only after this interval are all the accumulated pieces retrieved and analyzed collectively as a single context.
This enables the AI to grasp the complete intent behind the conversation, rather than offering premature responses based on incomplete information.
It also handles mixed media gracefully. For instance, a user might send:
- A short text requesting an appointment.
- A voice note specifying their preferred time.
- A photo of an exam result.
- A PDF containing their medical history.
Each of these inputs is processed individually—voice messages are transcribed, images are interpreted using vision models, and documents are parsed—before everything is consolidated into a unified input for the AI to process.
This empowers the assistant to provide responses with depth, clarity, and contextual awareness. It doesn't merely react to a single message; it responds to the entire situation.
And that, I believe, is what truly differentiates an AI experience from a chatbot that simply reacts.
I would be very grateful for any assistance.
Posted : 28/05/2025 3:22 am