Notifications
Clear all
Features
19
Posts
15
Users
0
Reactions
268
Views
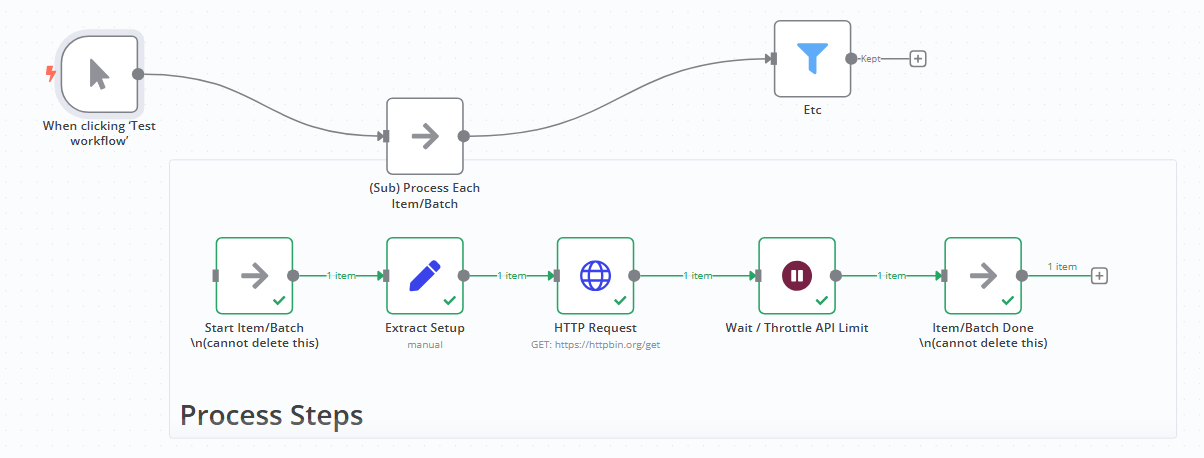
I wish the UI provided no option for failing to “close” the loop, and made it clearer that every item entering the loop should proceed to the end somehow. This is because placing an If or Filter within a loop seems as problematic as nesting another loop. Sometimes, the workaround is to extract the steps within the loop into a callable sub-workflow, making it a single step. However, this can make tracing through executions more difficult.
From my understanding, the primary reason for using a loop-over-items is to avoid the “process everything immediately, in one go” behavior that a node exhibits with a list of items.
What if loop-over-items were reframed as an in-workflow “batchable” sub-process.
Posted : 26/03/2025 11:34 pm
- Include error output data; if active, instead of interrupting the loop, place the item with the issue in the error output and proceed with the other items.
- Introduce an offset setting to bypass one or more items within the loop.
- Add an execution time option to halt a loop if it exceeds a specific duration.
- Provide mockup data for setting custom JSON elements for loop testing.
- Incorporate an option for reverse looping, where the loop node waits for all items and then begins processing from the last item.
Posted : 27/03/2025 10:20 pm
I'd appreciate an option within the loop configuration to receive only a completion status, rather than all loop results.
This would help streamline the response, making it a cleaner trigger for subsequent actions.
![]()
Posted : 28/03/2025 1:12 pm
First issue: The way nodes reflect item counts is quite peculiar. Consider nested loops: if a single item processed within a loop generates four sub-items (like a split), and then you loop over those four items, the counts can escalate to very large numbers, almost like a Cartesian product.
Observe the example: with 15 items in the main loop, for each item, four new items are created and processed. Upon returning to the main loop, where does the 480 count originate?
A second, related issue: it appears that loop outputs are retained across different runs. While this is beneficial, counting and displaying them isn't as practical. In my opinion, few users loop over thousands of items solely to collect them for a subsequent action. Although it's possible, collecting a large number of items can, in some scenarios, lead to OutOfMemory errors or even complete data loss if something fails. We often use batching to perform actions step-by-step, commit, and then loop (which is just one method of handling item processing).
Posted : 28/03/2025 2:24 pm
Page 2 / 2
Prev