Notifications
Clear all
Features
14
Posts
4
Users
0
Reactions
124
Views
Topic starter
I'm curious if it's possible to connect a couple of different node types to serve as a knowledge base for the AI. The first is Google Drive. In the setup, I can select the resource as a folder, but under operations, I don't see an option to read or index. So, can a folder be configured for reasoning?

Additionally, I've noticed AI nodes but not an AI tool. A colleague created a GPT in our OpenAI team account and shared it with me. This GPT is designed to handle customer requests. Is it feasible to set up an AI tool that utilizes this GPT?
Here's my current workflow.
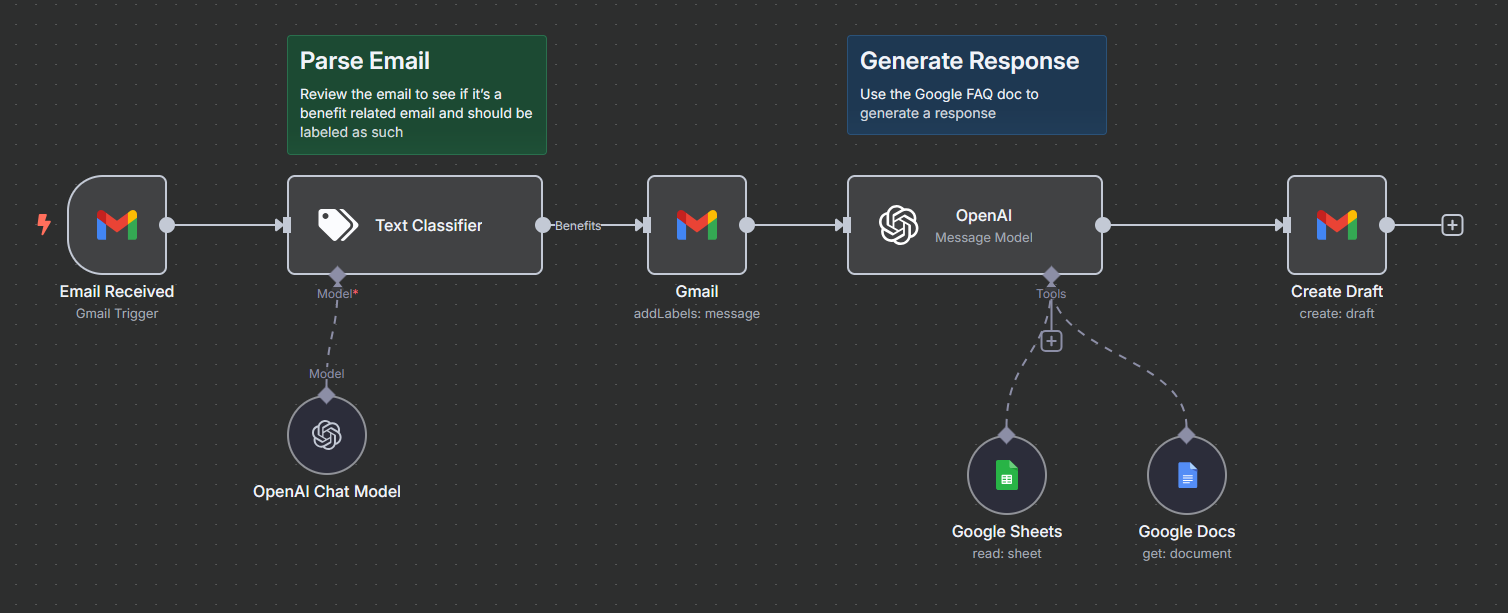
callin.io version: 1.91.2 running in the cloud
Posted : 05/06/2025 4:37 pm
You may need to retrieve all files first and then pass them to the OpenAI model.
It's not possible to just list the folder.
Posted : 05/06/2025 4:52 pm
Yes, You Can Use a Google Drive Folder as an AI Knowledge Source in callin.io — Here’s How:
While callin.io doesn’t have a one-click “index folder for AI” feature, you **can absolutely configure it to read documents from a Google Drive folder and feed the content into an AI model like OpenAI for reasoning.
Posted : 06/06/2025 5:04 am
Topic starter
I apologize, but your guide doesn't offer sufficient information for me to understand how to achieve this. Could you please share more details on configuring the Google Drive tool to read from a specific folder and then pass that data to the AI? Thanks!
Posted : 06/06/2025 11:27 am
Step-by-Step Setup in callin.io:
-
Connect Google Drive
Use the Google Drive node.
Set the resource toFileand use the operation:List.
Specify the folder ID to retrieve all files in that folder. -
Read Each File
Use a Loop or SplitInBatches node to iterate through each file.
For each file:- Use
Google Drive→Downloadto get the file contents. - Use the
Binary to Textnode to convert file content (PDF, TXT, etc.) to plain text.
- Use
-
Send to OpenAI (or other LLM)
- Add an OpenAI node (or HTTP node calling OpenAI API).
- Pass the plain text content from each file as part of the prompt (or optionally summarize, chunk, or embed it).
Posted : 06/06/2025 11:42 am
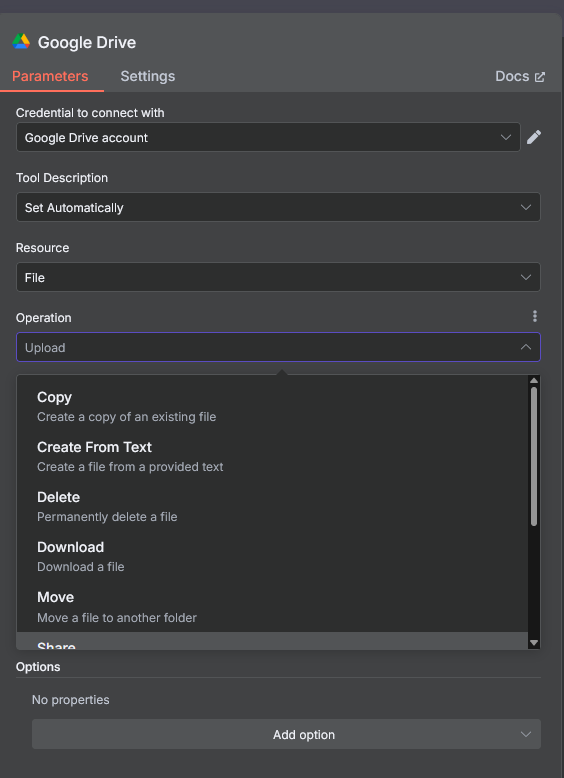
Hi,
To retrieve all files, utilize the search operation. You can leave the query field empty, and it will return all files. If you need to specify a particular folder to fetch files from, you can also indicate that folder.
It will return one file as a single item, so a split in batches node isn't necessary. The subsequent node would then iterate through each item.
Here's an example:
Posted : 06/06/2025 1:15 pm
Would you like me to share the link to my Google Doc, which contains the detailed solution for this?
Posted : 06/06/2025 4:55 pm
Topic starter
I appreciate your help with this.
Posted : 06/06/2025 8:50 pm
Topic starter
Thanks. So then, where would the output of the second node be directed to ultimately serve as a knowledge base for the AI?
Posted : 06/06/2025 8:51 pm
It connects directly to the AI agent. The AI node includes an option named “Automatically Passthrough Binary” which sends the data to the agent. It has been enabled in the example below.
To provide all the data to the AI agent in a single execution, you can insert the aggregate node after the second node.
If this was helpful, please consider marking it as solved. Thanks!
Posted : 06/06/2025 9:23 pm
Topic starter
Thank you. I apologize, but I'm struggling to fully grasp how this will function as the tool for my AI agent within my current workflow. Here's a look at my setup after incorporating your suggestions. How can I connect it so that my existing OpenAI node, which generates responses based on Google Docs and Sheets, also utilizes the Drive files as a tool? And yes, I agree that passing all files simultaneously would likely be the most effective approach, so is my aggregate node positioned correctly? Thanks again.
Posted : 09/06/2025 11:58 am
Topic starter
Could you please share the link to your Google Doc? Thank you.
Posted : 13/06/2025 12:11 pm
Posted : 16/06/2025 7:59 am