Notifications
Clear all
Topic starter
Hi, when I check the logs of my AI agent (which uses chat memory and the OpenAI chat model), I see that the input payload sent to the chat model looks like this:
{
"messages": [
"System: my system promptnHuman: hinAI: {"output":{"text":"how can I help you"}}nHuman: I need info about dogs"
]
// ... other metadata omitted
}
This single message string includes:
- 1 system prompt
- 1 pair of human/AI messages from chat memory
- 1 human message from the user message
My question is: If the payload is being sent as a single string, wouldn’t it be more optimal for the LLM to format it with clear section headers? For example:
System: my system prompt
# Chat history
Human: hi
AI: {"output":{"text":"how can I help you"}}
# Latest user message
Human: I need info about dogs
Would this kind of structure help the LLM better interpret the context, or is the current format (no sections) already optimized for the model’s input parsing?
Posted : 10/05/2025 1:52 pm
Yes, this aids LLMs in understanding context, roles, tools, and most importantly, the instructions needed to provide answers.
Since LLMs are probabilistic models, providing more insightful prompts and instructions means offering better input. This allows the LLM to understand more effectively, increasing the probability of solving your problem.
Posted : 10/05/2025 3:46 pm
Topic starter
Appreciate the insight! Is there a method to tailor this for the AI agent node? Currently, it appears to transmit the complete chat memory and the user's message as a single unit, lacking any headers. I haven't discovered a way to implement custom header formatting, similar to the second example provided.
Posted : 10/05/2025 11:53 pm
You can attempt to parse from Memory, reformat the chat Memory, then add your prompt and send it to the LLM.
Posted : 11/05/2025 6:35 am
Hi everyone,
You're not alone in overthinking this.
![]()
I believe the logs are showing a simplified view of the internal processes.
The history isn't just a string; it's an array of message objects, similar to any LLM conversation.
If you use an API that supports logging, you'll observe the final prompt loaded as a proper history, not a single string. LangChain manages the entire conversation.
If you're still interested, you can feed the AI Agent ToolsAgent file into any AI model to get a better understanding of the underlying mechanisms:
Posted : 11/05/2025 7:20 am
This is how it appears in the callin.io UI:
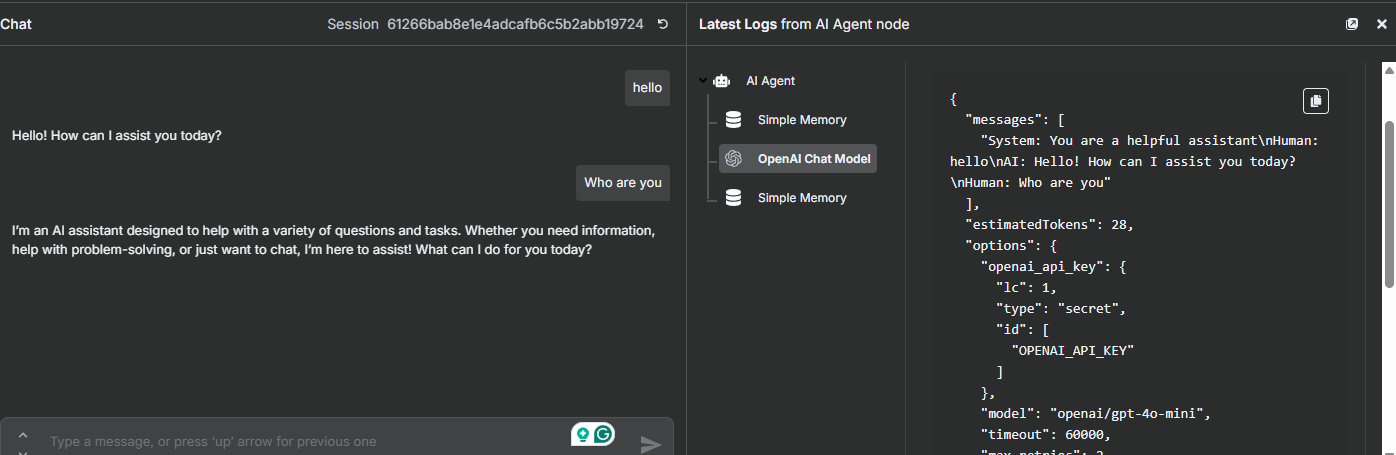
And this is precisely what is sent to the API, not as a string, but as an array of message objects.
For example, when I use Requesty.ai and enable logging, I can examine the API calls, and it matches exactly:
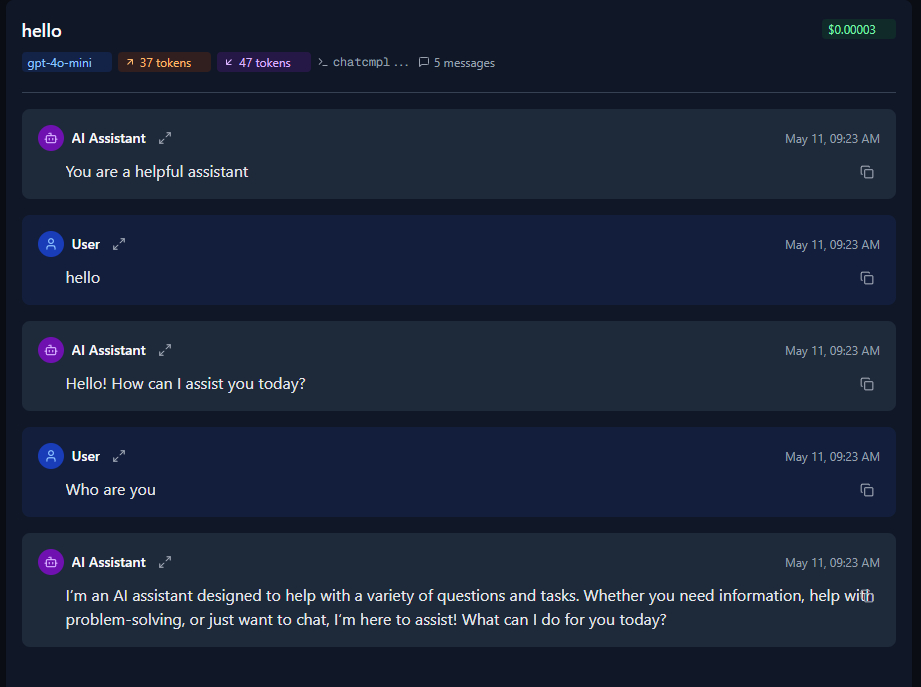
You can also observe that the system message is included within the messages.
Posted : 11/05/2025 7:30 am
Topic starter
Thanks! I've checked the OpenAI logs and confirmed that the conversation history is correctly segmented into multiple messages.
However, I'm encountering an issue where the LLM isn't analyzing the conversation history as expected. I've prompted it to review the chat history for answers before activating any tools. Despite this, it consistently calls tools even when the answer is already present in the chat. Has anyone else experienced this?
Interestingly, this problem resolves when I embed the chat history within the system prompt using a Chat Memory Manager. In that scenario, the model correctly adheres to the instruction to avoid calling tools when the answer is already available in the history. For this to work, I wrap the chat history with <chat_history> HTML tags and refer to it as chat_history.
Here's an excerpt from the prompt I'm using:
<instructions>
Follow these instructions strictly and in sequence. Stop the process at the first step where you must respond to the user:
1. Before responding, review the message history to check if the user's question has already been answered. If the answer exists, reuse it verbatim without activating any additional tools.
2. Analyze the user's message and understand their intent using all available context from the conversation/chat.
3. If you have enough information to generate a useful and relevant response, reply directly to the user and stop the process.
4. If not, evaluate whether the ia_contacto tool needs to be activated to handle the request.
5. If ia_contacto is activated, respond using only the result provided by that tool.
6. If ia_contacto was not activated, consider whether you should activate the base_conocimiento tool.
7. If base_conocimiento is activated, generate the response using only the information retrieved through that tool.
</instructions>
Here's an example illustrating the issue:
Conversation:
- User: What is the price?
- base_conocimiento tool: The price for the services is 400€
- AI: The price is 400€
- User: What is the price?
- baseconocimiento tool: The price for the services is 400€ ← _This tool call shouldn’t happen
- AI: The price is 400€
Posted : 11/05/2025 10:03 am
I believe this likely occurs because the memory manager incorporates the full chat history, whereas without it, the model only perceives the recent context within the window limit.
However, I suspect that if the model isn't reasoning effectively, it might invoke tools unpredictably...
Incorporating something like a “Think Tool” could potentially foster more deliberate processing...

That being said, it might introduce additional latency.
One potential optimization is to encapsulate the Chat Memory Manager within a sub-workflow configured to output the price, if it's available...
Then, include this tool within your <instructions> and explicitly direct the model to invoke it before utilizing base_conocimiento...
Posted : 11/05/2025 10:34 am
This thread was automatically closed 7 days following the last response. New replies are no longer permitted.
Posted : 18/05/2025 10:34 am