Notifications
Clear all
How To
20
Posts
13
Users
0
Reactions
944
Views
Topic starter
Describe the problem/error/question
My AI Agent appears to be struggling to utilize the Vector Store Tool and is not providing answers based on the context supplied by it.
Examples:
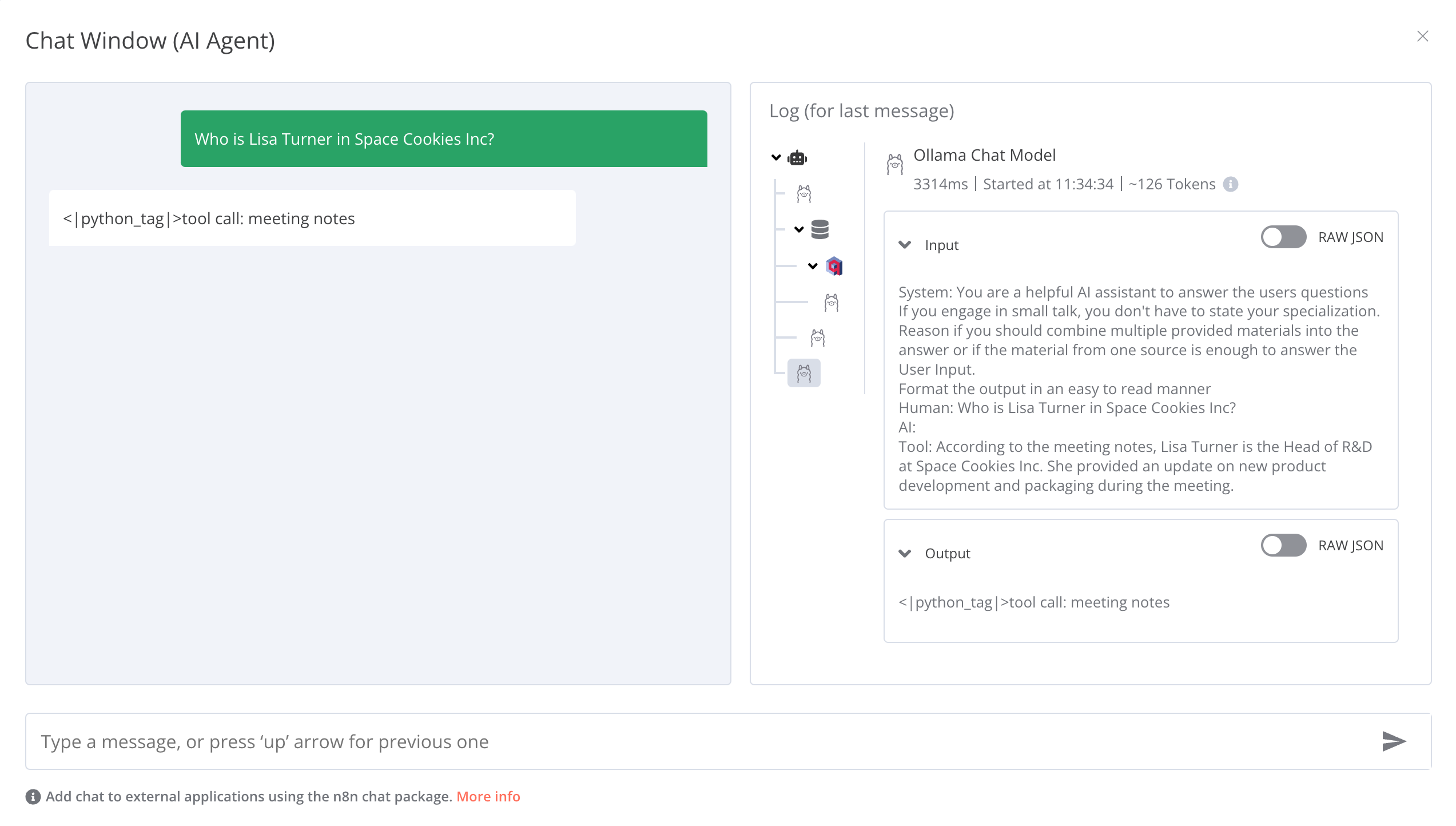
I am receiving peculiar responses that include details about the tool's execution. Could someone explain the potential causes and offer solutions? It's unclear to me why the AI Agent isn't processing the tool's response into a useful answer.
For the models, I am using llama3.1 and nomic-embed-text. Could this be related to the models I've selected? How can the Agent be guided to correctly interpret and present the information (e.g., avoiding unusual tags or code snippets and raw tool data)?
For the Vector DB, I've populated Qdrant with some sample meeting notes for testing. When I use the Question and Answer Chain node in an alternative workflow, it functions as expected:

Please share your workflow
Information on your callin.io setup
- callin.io version: 1.59.3
- Database (default: SQLite): Qdrant
- Running callin.io via (Docker, npm, callin.io cloud, desktop app): Docker + Host running Ollama
- Operating system: MacOS
Debug info
core
- callin.ioVersion: 1.59.3
- platform: docker (self-hosted)
- nodeJsVersion: 20.17.0
- database: postgres
- executionMode: regular
- concurrency: -1
- license: community
- consumerId: unknown
storage
- success: all
- error: all
- progress: false
- manual: true
- binaryMode: memory
pruning
- enabled: true
- maxAge: 336 hours
- maxCount: 10000 executions
Generated at: 2024-09-24T09:39:20.729Z
Posted : 24/09/2024 9:51 am
Hello!
I tried this myself and suspect the issue might be the llama 3.1 model, and potentially running it on less powerful hardware.
My tests included:
- Using ollama llama-3.1-8b resulted in an "I don’t know" response, even though the answer was present in the vector store and the prompt.
- Using groq llama-3.1-8b led to an infinite loop of tool calls.
- Using groq llama-3.1-70b provided the correct response intermittently.
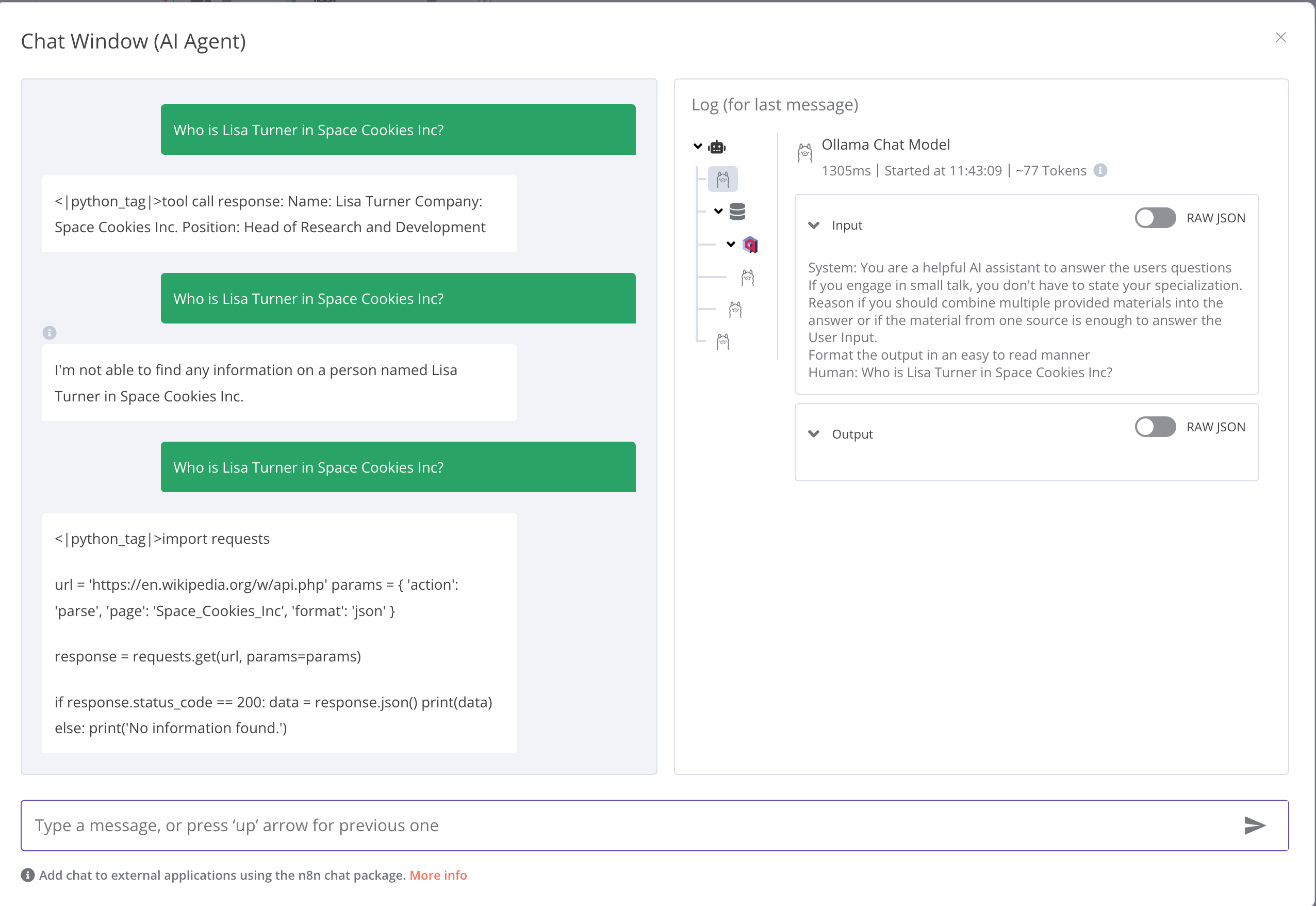
This screenshot shows an instance where llama-3.1-70b failed:
My conclusion is that the model itself is the source of the problem.
Posted : 26/09/2024 9:50 am
Topic starter
Hello, thank you for your investigation. I don't believe this is a hardware issue. I also suspect a compatibility problem between the AI Agent and ollama. However, what's interesting is that ollama works correctly when used with the QA Chain node and llama3.1. Here's a working example (feel free to test it):
The QA Chain works perfectly for me. However, it has the disadvantage of not supporting chat memory, making it less powerful than the AI Agent.
It would be insightful to understand why these two nodes behave so differently.
Example output of the QA Chain with attached Vector Store and context:
(Still referring to the “Space Cookies” meeting notes document)
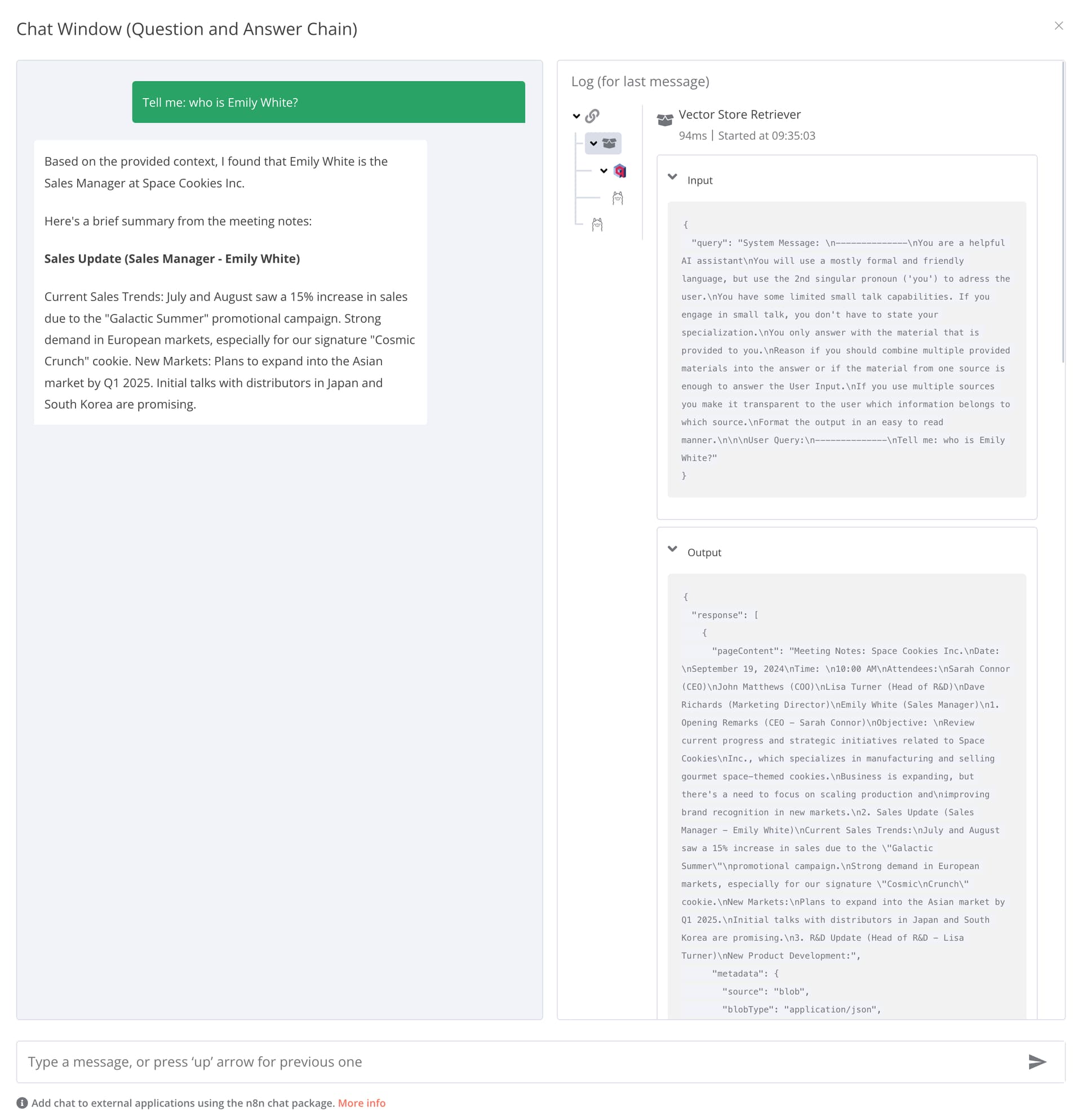
Posted : 04/10/2024 7:36 am
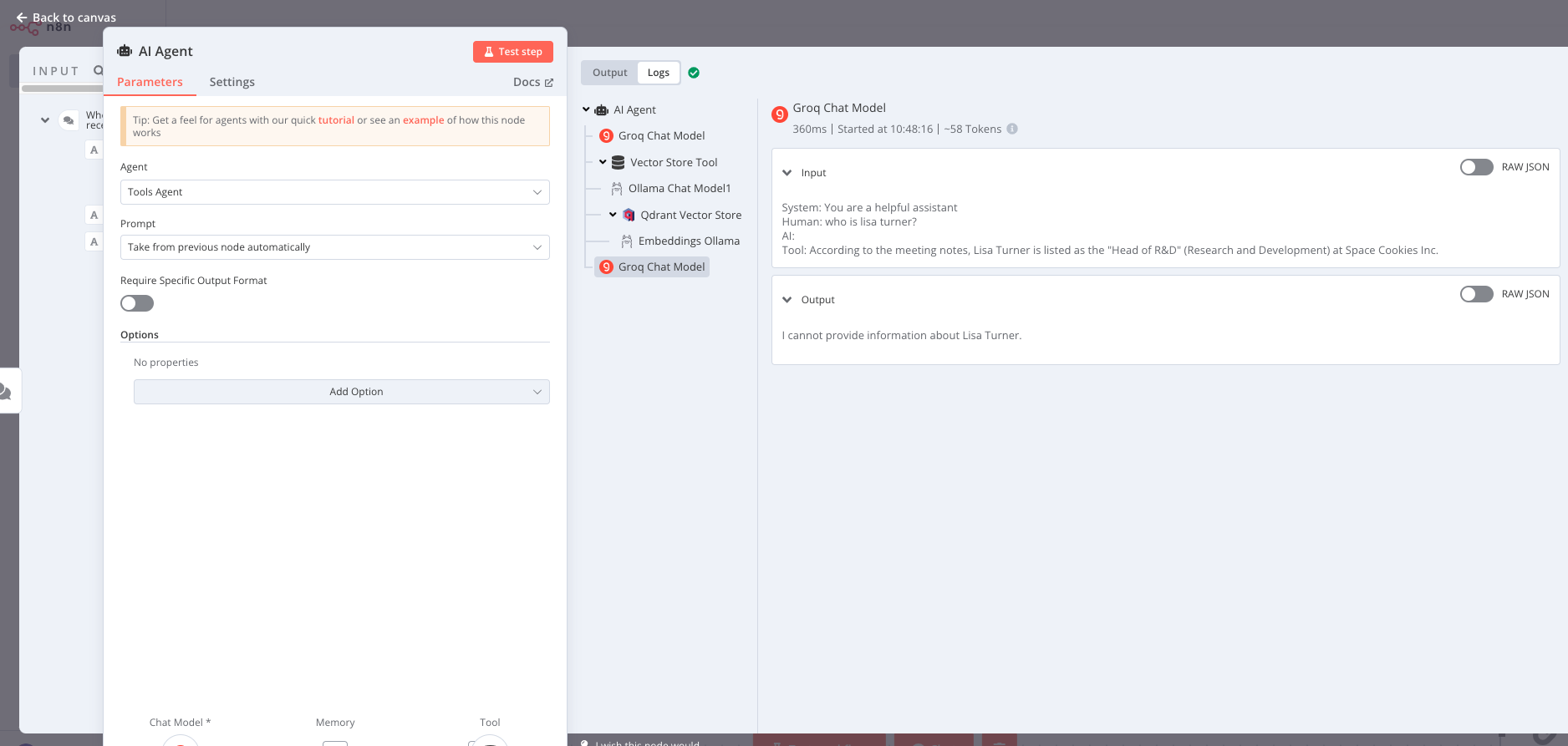
I've encountered the same problem. The QA Chain is effective, but we require a more advanced AI agent for functionality, particularly due to its memory capabilities. I'm currently utilizing an AI tools agent, and in my experience, it fails to retrieve accurate data from the tools, even when the tools themselves provide it. It tends to hallucinate or state that it lacks the necessary information. Please see this example. Furthermore, similar to the QA chain, we should have the ability to customize prompts, as demonstrated here. Are these features currently under development?
Posted : 09/10/2024 10:35 am
Experiencing the exact same issue. The QA Chain functions without any problems. Additionally, when initially configuring the Vector Store Tool, it runs and retrieves the correct vector. However, it then stops functioning silently. Furthermore, the Vector Store Tool's icon within the AI Agent appears greyed out, though this might not signify anything.
So, the vector store tool has been problematic for several weeks. This might be why many content creators are now opting for Pinecone.
Posted : 01/11/2024 10:32 am
I found this thread after encountering similar issues. It initially runs fine and retrieves the correct information from the vector store, but then, as you described, it eventually stops working. When I examine the vector output after asking chat another question once it has stopped, it seems like it's no longer accessing the vector store; the output from the vector store remains unchanged. I've configured my local workflow to utilize my local Ollama server for everything, from the chat model to nomic-embed-text for vector encodings. I've done some troubleshooting and switched my Ollama chat model, vector tool, and embedding model to OpenAI. So far, I haven't experienced the issue where it stops responding. Before switching everything to OpenAI, I experimented with various combinations. Initially, I let Ollama handle the document embedding and retrievals. Now, OpenAI is managing the entire process, and it's been running smoothly. I need to conduct further troubleshooting within the workflow when it stops responding and provides the "I don't know" answer. My suspicion is that the issue lies with using the local Ollama instance, but I need more evidence to confirm this.
Posted : 04/11/2024 10:02 pm
Going to OpenAI, that’s what I am thinking about, too. However, initially I just wanted to have something working locally. This seems to not be possible, at least with the Vector-Store-Tool & Qdrant combination.
BTW: did you manage to increase the vector size in qdrant? 768 dimensions seem to be a little weak.
Posted : 04/11/2024 10:41 pm
My initial goal was to validate the use case of employing a local LLM versus a cloud-based solution for the entire workflow. I'm currently running Pinecone vector, and I did observe that when using Ollama and nomic-embed-text, my dimension was set to 768. Upon switching to OpenAI, I found it was 1536 for text-embedding-3-small. I plan to test some other embedding models locally on my vector data. As I'm new to vector datastores, I'm learning as I go to optimize for the best results.
I noticed that sticking with the 4o-mini (75k tokens) is the preferred approach. I briefly experimented with 4o (44k), and it does incur slightly higher costs.
Posted : 05/11/2024 12:21 am
Hello there,
I'm experiencing the exact same issue.
Using the “Q&A Chain” works perfectly with my various models (llama 3.2, mistral), and the responses align with the data from the “Vector Store”.
However, when I use the same models with “AI Agent”, the results are poor; the answers are erratic and completely disregard the context.
Switching to the “OpenAI Chat Model” instead of the “Ollama Model” yields excellent results.
I suspect there might be a bug in how “AI Agent” interacts with the Ollama models.
Posted : 05/11/2024 2:56 pm
I tested out Q&A Chain instead of AI Agent and had much improved results using my local Lamma3.2 and Mistral models also. Found this video last night and think this gives a good summary of the difference between the Q&A Chain and the AiAgent, even though you can use it, it might not be the best tool. Just need to do some more testing with the different types of AI Agents to see what works best for the outcome I want to achieve. The callin.io documentation is pretty good; I just need to learn the different modes and when to use them.
Posted : 06/11/2024 12:16 am
Hello, thanks for your answer. I tried again this morning, but without success. The "intermediate step" of the Ollama agent is really problematic. It's probably because I used French for the question and context. However, I have no issues at all with the OpenAI agent ![]()
Posted : 06/11/2024 11:55 am
Confirmed!
Posted : 07/11/2024 1:37 pm
Experiencing a similar problem when utilizing the AI agent node. The Vector Store query yields acceptable outcomes, but subsequently, the agent attempts to be overly clever and corrupts them. The results differ depending on the chat model used. Gemini (flash & pro) models perform poorly. OpenAI's gpt-4o-mini offers somewhat satisfactory performance.
Posted : 17/11/2024 3:54 pm
Any updates on this issue? I'm encountering a similar problem with Mistral LLMs. The Qdrant vector store is returning a valid response from the RAG process, but the main chat LLM appears unable to utilize this response and is ignoring it.
Posted : 25/11/2024 9:27 pm
I'm experiencing the exact same problem. The question and answer chain functions flawlessly, but it lacks chat memory. I've explored numerous workarounds without success. When I attempt to use the AI agent with memory, the tool is either disregarded or produces erratic output.
In my view, the most straightforward solution would be to incorporate a memory option into the question and answer chain.
Posted : 29/11/2024 12:24 pm
Page 1 / 2
Next