Notifications
Clear all
How To
20
Posts
3
Users
0
Reactions
1,057
Views
Topic starter
Hello everyone,
I've reviewed several discussions on 'combining outputs' within this forum as I work on aggregating markdown content. However, none of the existing topics precisely match my current objective, so I'm starting a new thread.
My goal is to query an AI about a company using only information from its website. Here's my current workflow:
- Perform an HTTP request to the main domain – Successful
- Retrieve all links referenced on the main domain via an HTML request (77 links) – Successful
- Remove duplicates and filter out irrelevant links, leaving 69 links – Successful
- Fetch the HTML markdown for all 69 links – Successful
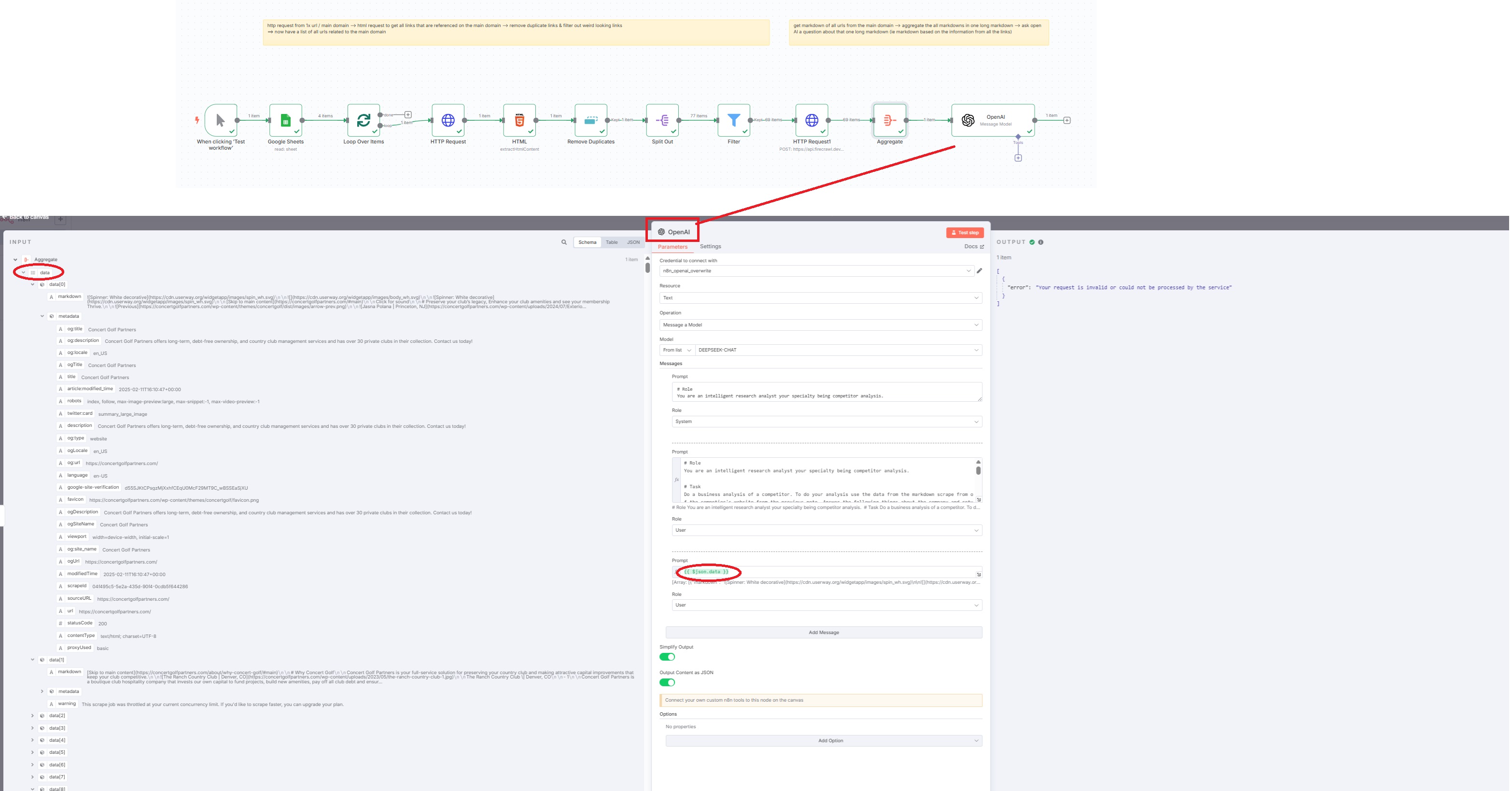
- Aggregate the 69 markdown contents into a single object
{{ $json.data }}so I can later ask AI questions about the entire website – Successful - This is where the issue occurs: In the final step, I attempt to ask OpenAI questions, referencing the single object
{{ $json.data }}from the preceding node. I'm encountering an error: "error: your request is invalid or could not be processed by service" (refer to the screenshot). If I reference{{ $json.data[0].markdown }}instead, it works, but the AI will only consider the markdown from one of the 69 URLs. I suspect that using the 'aggregate' function to combine the markdowns might be incorrect. I've experimented with other functions, but none have resolved the problem.
I would greatly appreciate some guidance on this matter!
Thanks,
Felix
Posted : 31/05/2025 4:15 am
Within the Aggregate Node.
You should utilize the markdown field.
This will provide you with an array of the markdown field.
In the OpenAI node: Employ {{ $json.toJsonString() }}
Posted : 31/05/2025 6:24 am
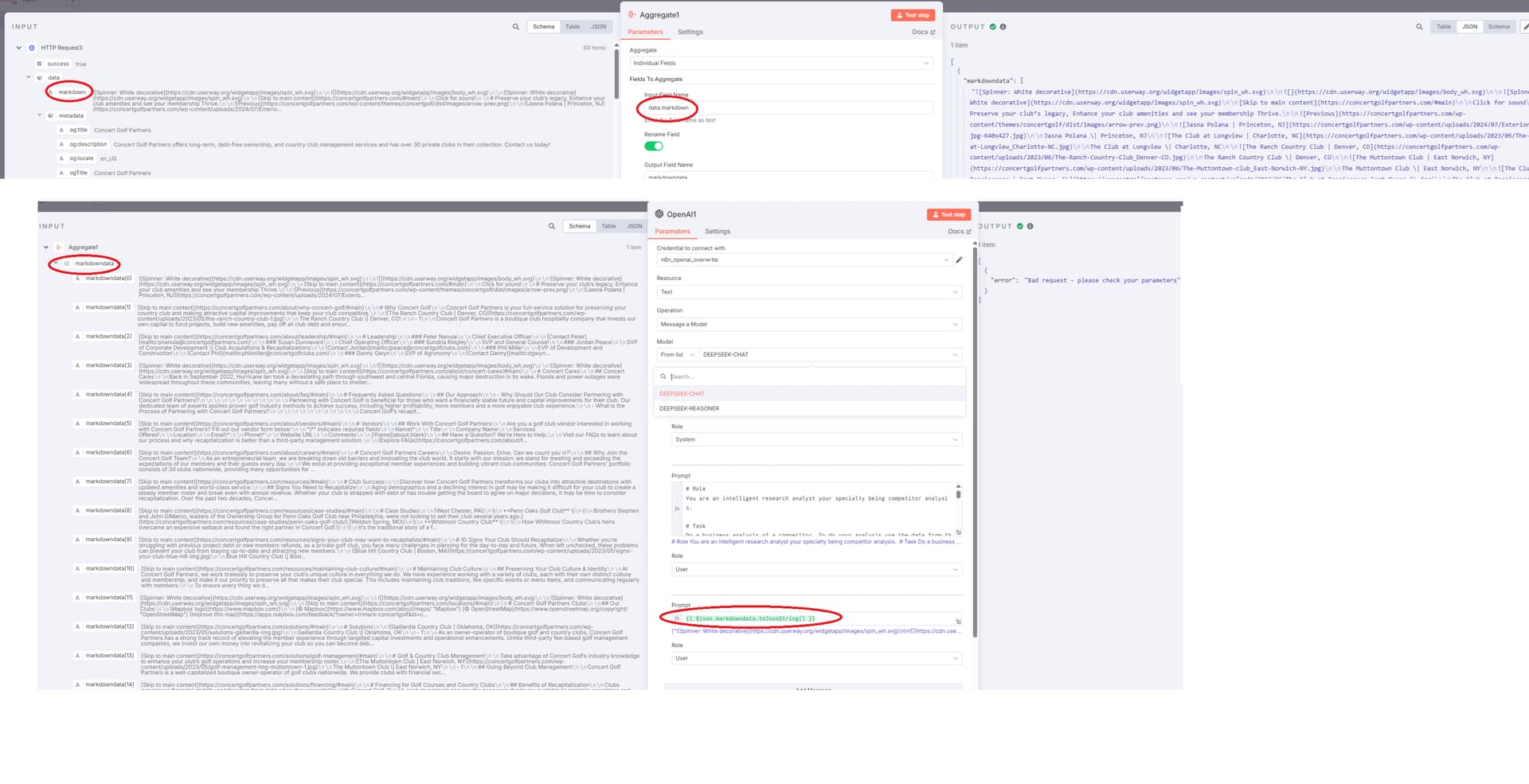
In this scenario, I suspect the issue might be with Deepseek.
Since the prompt appears to be fine now, do you have another model you'd like to test?
Please provide the rewritten markdown content.
Posted : 31/05/2025 11:08 am
Topic starter
That's peculiar. The ChatGPT/OpenAI prompt functions correctly when linked to a single markdown file, rather than an array of multiple markdown files. Therefore, I don't believe the issue lies with ChatGPT/OpenAI. It appears that the automation logic isn't quite flowing as expected yet.
![]()
Posted : 01/06/2025 7:07 am

Topic starter
Hey Dan, apologies for the delayed response; I wasn't feeling well. I'm happy to share the workflow in a comment, similar to your example, but I'm unsure how to do it. I have the paid version of callin.io and see the share button, but I don't know how to integrate it here in the chat. The documentation (Sharing | n8n Docs) and other related posts (How do I share a workflow? The documentation doesn't relate to product - #2 by romain-n8n) haven't been helpful. I apologize, I'm still quite new to this. The workflow ID is #qn57AohkchAcLgtm. Does that assist you?
Posted : 03/06/2025 10:34 am
Topic starter
The issue still persists. If you have a moment to share your expertise, I would greatly appreciate it.
![]()
Posted : 10/06/2025 8:18 am
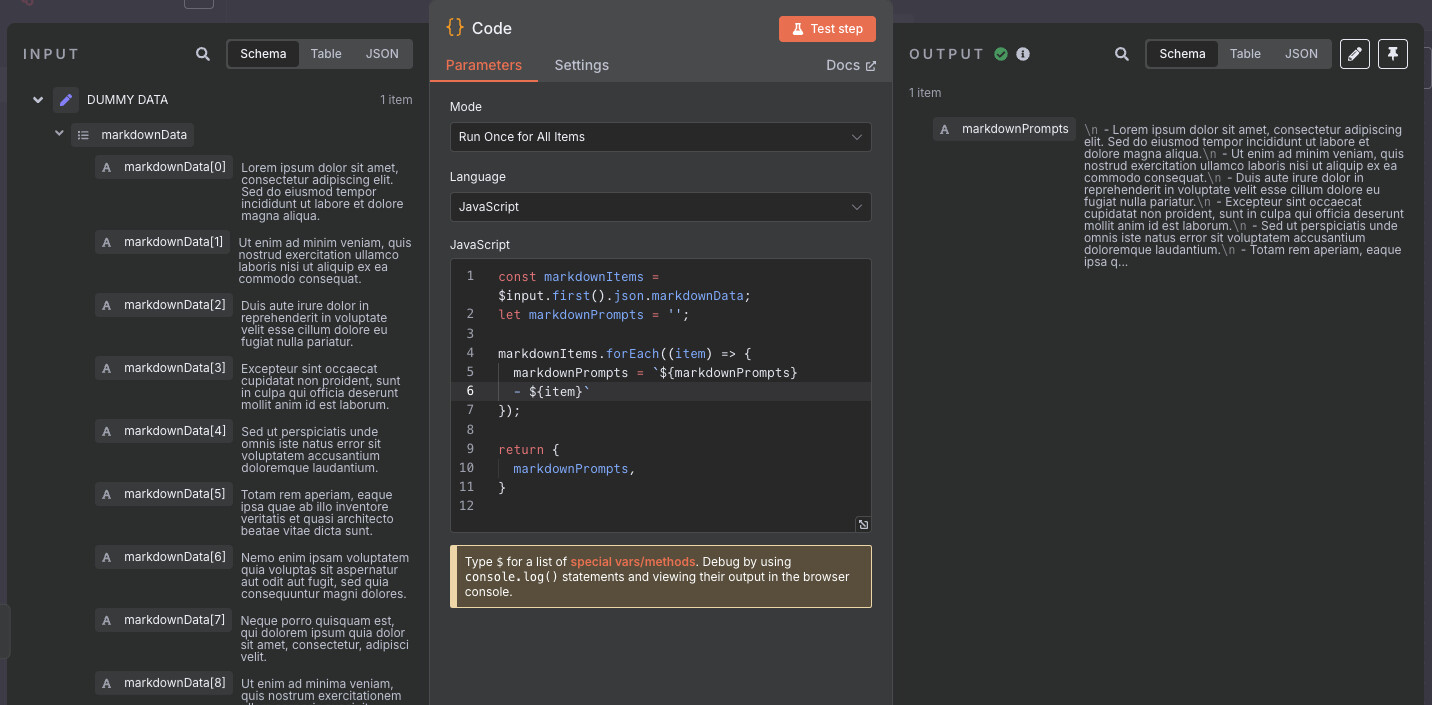
Topic starter
It works, thanks a bunch Wouter!!!
For anyone who is reading this, the short of it: AI agents cannot work with arrays. Convert the array into a string using the code snippet that Wouter suggested. The AI agent can work with the string.
Posted : 11/06/2025 4:29 am
I'm having trouble distinguishing between using Aggregate and toJsonString().
It seems quite similar if the goal is to convert an array into a single string.
However, I agree that any method that aids your workflow is a valuable one.
Posted : 11/06/2025 5:17 am
Topic starter
Thank you all!
Posted : 11/06/2025 5:21 am
No, that's not the case. You need to grasp how callin.io manages data. It can either return multiple items, for which the subsequent node will execute for each one, OR, by using the aggregate function, instead of executing the next node multiple times, it will generate a single output item of an array type. The issue encountered was that the AI node anticipates a STRING, not an ARRAY.
Reading this will provide a more detailed explanation:
Posted : 11/06/2025 8:21 am
Topic starter
Hello,
Apologies for the potential scope creep, but I have a related question and you seem knowledgeable. Could I trouble you for some insights on the following?
![]()
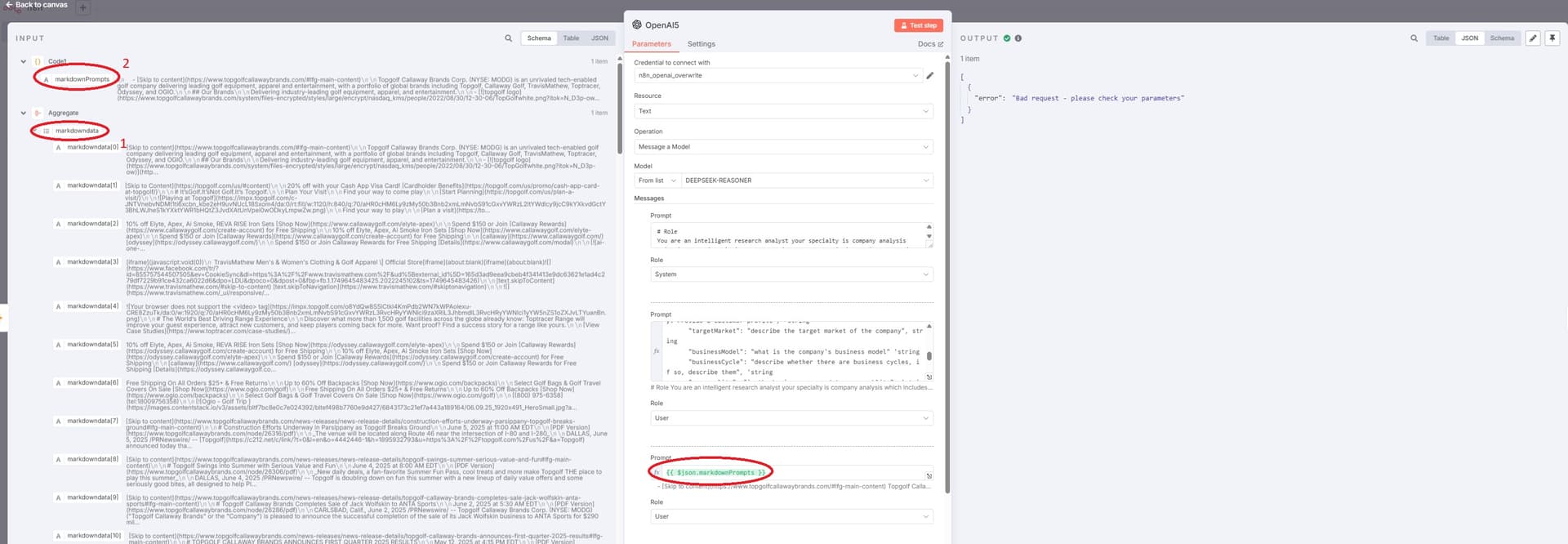
I followed your advice:
- I take the aggregated markdown data, which is an array named 'markdown'.
- I use code to successfully convert it into a string called 'markdownprompt'.
- Then, I pass the 'markdownprompt' string to OpenAI for processing. The issue is that while it works for most websites, sometimes it fails with an 'error - bad request' output. Do you have any ideas what might be causing this? One possibility is that the content of 'markdownprompt' might be too lengthy.
If I'm overstepping, my apologies, and please disregard this. You've already been a great help!
Posted : 11/06/2025 2:45 pm
No problem at all, we’re here to assist where we can. Could you please share your updated workflow in a code block? It’s challenging to make an accurate assessment based on your current setup. What is the size of the markdownprompt value for the instances that fail? If the issue is intermittent, it’s most likely due to a context window limitation. Which model are you currently using? What are you aiming to accomplish with the AI call, etc.? There might be a more effective and efficient approach to handle this issue logically.
Revisiting your original question, if your primary goal is to scrape company information from a website and then extract data from it, a RAG solution would be a superior and more efficient method for querying the data.
Kindly watch this video and pay close attention to the demo at the beginning where the presenter explains the problem it solves, to see if it would be suitable for your use case.

Posted : 11/06/2025 5:16 pm
Page 1 / 2
Next