Notifications
Clear all
Topic starter
Hi! I'm trying to set up an automation that was featured by callin.io a month ago, which performs the following actions:
- Gong monitors for new calls.
- Gong retrieves the audio transcript.
- The text is iterated and aggregated into audio.
- An AI summarizes it.
- This summary is posted to Slack.
My question is how I should capture the call media and have it aggregated into audio?
The example highlighted in the post made by callin.io can be found here: callin.io on LinkedIn: Uncover market intelligence with Gong
I would greatly appreciate some assistance with configuring the Gong, Iterator, and Tools modules! I believe I can manage the AI and Slack modules once those are set up.
Any help is appreciated! Thank you!
When asking your question, please include:
The steps you have taken
Relevant screenshots
Any links you have
[ Code { "and": "JSON", "in" : "code block"} ]Exclude Personal Information.
Posted : 26/07/2023 4:11 pm
Hello! Thanks for asking.
A comprehensive, step-by-step guide for this was published in our use-case repository, which should cover all your needs.
If you're interested in broader AI applications, you might also consider using Eden AI as an interface for your chosen AI solution. They offer a unified API for various AI tools and a single billing point, simplifying the comparison of outputs from different engines. There's also a callin.io app available!
Posted : 27/07/2023 9:52 am
Topic starter
Hello!
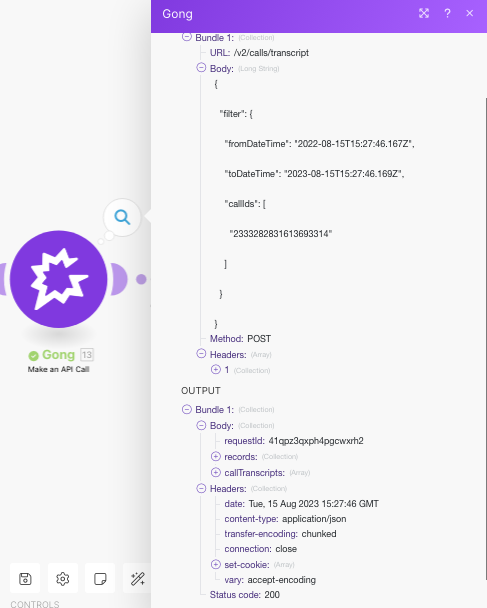
I'm encountering an issue with aggregating call transcripts using the current tutorial. I've followed the template and used the provided JSON, but it seems only the initial sentence of the call is being captured.
I've verified the call itself, which is 22 minutes long, so the issue isn't with the call duration.
Could you please advise if there's an error in the tutorial or my setup that's causing this? I'm attaching the blueprint.json file along with screenshots of the module settings for your review.
Any assistance would be greatly appreciated!




blueprint.json (25.8 KB)
Posted : 15/08/2023 2:34 pm
I can’t see any obvious error, but I don’t have any Gong call records in our sandbox to test with.
If you run the scenario, you can then click on the “speech bubbles” to the top right of each module to see exactly what it returned. Take a look at the results of the callin.io API Call module, the Iterator, and the Text Aggregator.
If nothing jumps out to you, copy and paste screenshots from each of those and post here.
Posted : 15/08/2023 3:15 pm


Topic starter
Actually, when I examine the Call Transcripts Array within Bundle 1, I can see all the bundles from the transcript. However, when I proceed to the Iterator, my only option is to select sentences, which results in only one sentence being returned, not the entire array.
Do you think there's a workaround for this?


Posted : 15/08/2023 3:41 pm
Yes, that appears to be the case.
For the Make an API Call module, please expand the callTranscripts element completely.
Within that, you should find a transcript array, which contains an array of sentences.
Posted : 15/08/2023 3:56 pm
Topic starter
Yes, I understand.

However, when I select sentences for the iterator, as shown in the attachment, it's only returning one bundle in the array.

I suspect this is due to the transcript from the API call not reaching the iterator for some reason.

I'm not entirely sure if there's anything else you can do without perhaps scheduling a call to demonstrate.
Unless you have any other suggestions, would you be open to arranging a call?
Thank you very much.
Posted : 15/08/2023 4:58 pm
Hi there.
It appears there might be an issue with the initial use case setup.
The Gong API documentation indicates (under Response, when expanding each "...") that the callTranscripts array contains one entry per call. Each entry includes a transcript array, with one entry per monologue, which in turn holds the sentences from that monologue.
The term "monologue" is significant here – a new transcript is generated each time the speaker changes. The example in the use case only captures sentences from the first monologue, which in your scenario is limited to "Can you hear me?".
To address this, you'll need to insert an additional Iterator module between the Make an API Call module and the existing Iterator module.
The new Iterator will be responsible for processing the transcript array:

The original Iterator should then process the sentences from the newly added Iterator:

Finally, the Text Aggregator needs to be configured to aggregate all items from the new Iterator:

If this adjustment resolves the issue, please confirm, and we will proceed with updating the published use case.
Posted : 16/08/2023 9:05 am
Topic starter
IT WORKED!
Thank you so much for this - it's incredibly helpful for our team!
So glad we were able to get this working.
I appreciate all of your help!
Posted : 16/08/2023 12:57 pm