Notifications
Clear all
Topic starter
Hello,
I've developed a workflow designed to download .mp3 files from an FTP server and then send these downloaded files to Modjo.ai, a conversational analysis tool, utilizing Modjo's API.
The workflow is structured into two main parts:
- Part 1: Retrieve the URLs of all .mp3 files intended for download and store them in a database.
- Part 2: Iterate through this database one by one. In each iteration, download the .mp3 file from the FTP server and transmit the downloaded file to Modjo.ai via its API.
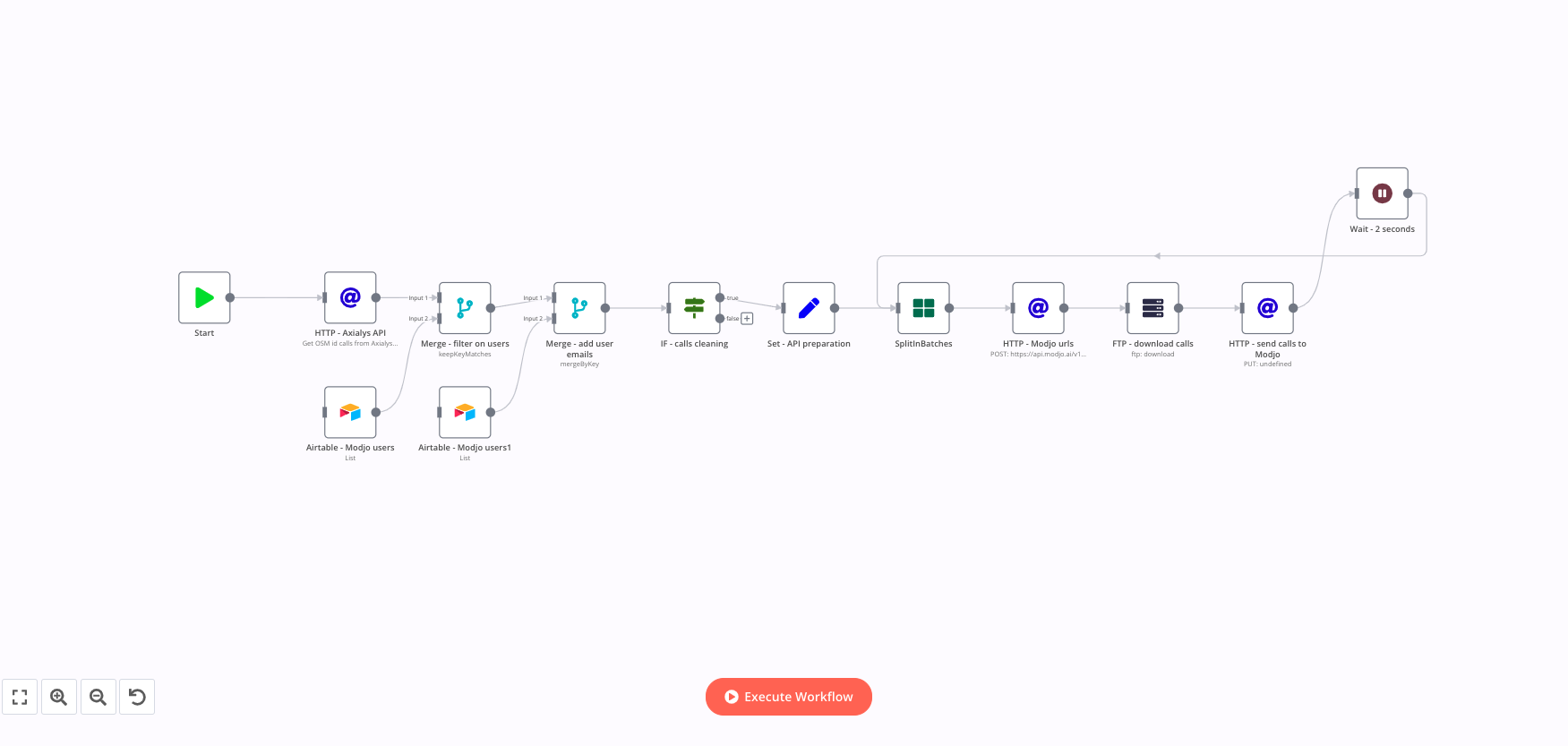
I initially set up this workflow using the callin.io desktop application, and it functions perfectly when run locally.
However, when I transitioned to callin.io.cloud, the workflow halts after approximately 3 iterations of the SplitInBatches loop. It encounters a "Connection lost" error when attempting to connect to the FTP node for the third time.
—> Please review the video recording of the workflow for a clearer understanding of where it stops: Screen Recording 2021-12-29...
I'm quite puzzled as to why it fails when the workflow is executed on callin.io.cloud, given that it operates smoothly on my local callin.io desktop app.
What could be the underlying cause? How can I ensure it runs correctly on callin.io.cloud as well?
Details about my callin.io setup:
- callin.io desktop app version: 0.147.1
- callin.io.cloud version: 0.152.0
Thank you for your assistance,
Ludovic
Posted : 29/12/2021 11:12 am
Welcome to the community!
The reason will be that callin.io runs out of memory and so crashes. Depending on which subscription you have on callin.io.cloud, will it have more (largest plan) or less (smallest plan) memory.
The Desktop App uses your system memory, which will be much larger than the one the cloud instances have, and for that reason, it works fine.
We released with the latest version (0.156.0) an update to use less memory when working with binary data (it stores the data on the hard drive rather than RAM). That version is however not available yet on callin.io.cloud and also not possible to activate that setting yet. Should however become available soon.
For now, the best thing to do would be to split out the workflow part which works with binary data into a sub-workflow and make sure that this sub-workflow returns only minimal data. It should then work fine.
Posted : 29/12/2021 12:52 pm
Topic starter
Hello,
Thanks for your quick answer.
I think I may need a bit more info on how memory works in callin.io
![]()
If callin.io runs out of memory after 2 SpliInBatch iterations, is it possible to clear memory at the end of each SplitInBatch iteration.
Say in my case, clear from memory the downloaded mp3 file after it’s been sent to Modjo?
When reading this previous thread, it seems not possible. But maybe things have moved on since then? Error to import 500K rows to database. How to do?
Thanks,
Ludovic
Posted : 29/12/2021 2:24 pm
No, all data persists in memory throughout the workflow's execution. Therefore, you must either:
- Maintain separate workflows
- Utilize the upcoming binary data handling feature on the cloud version
Posted : 29/12/2021 2:37 pm
Topic starter
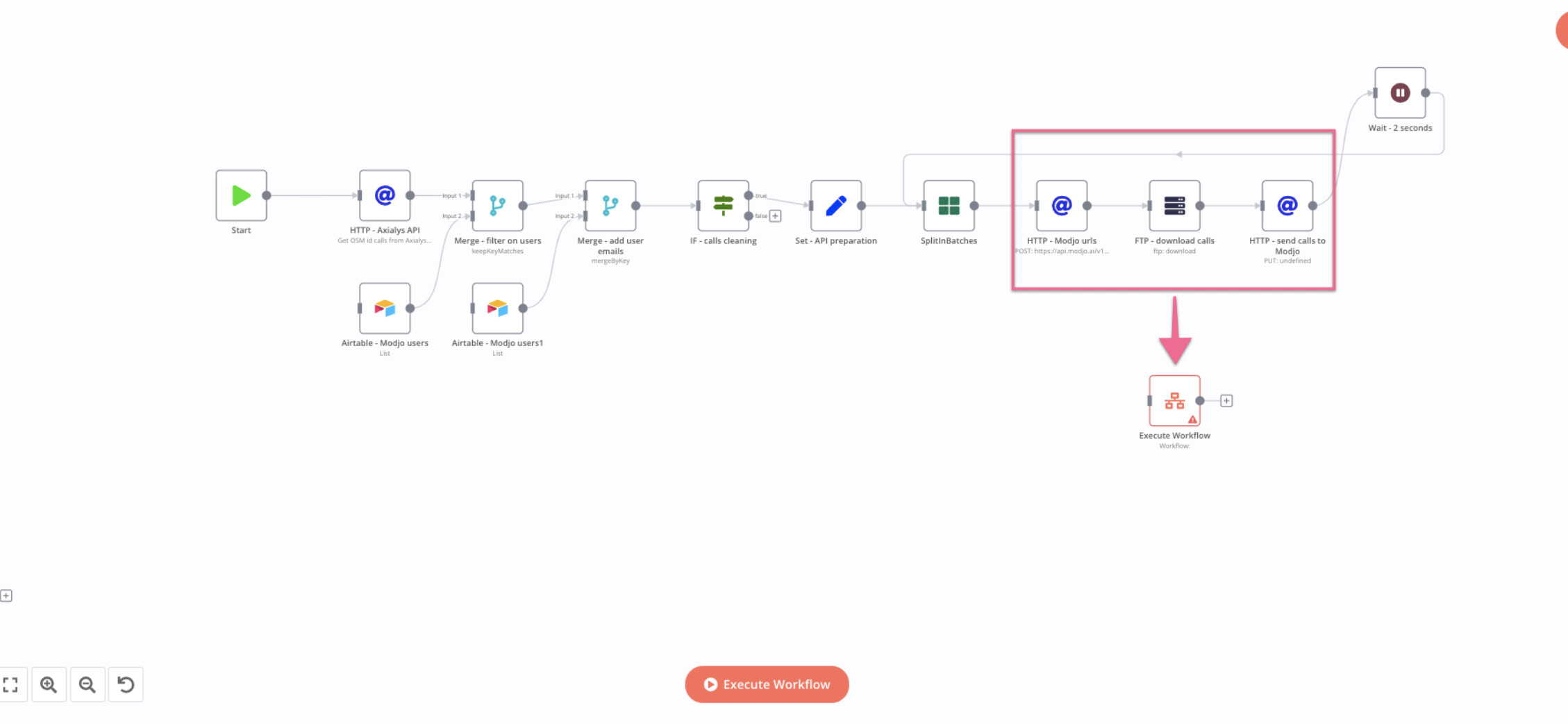
Regarding the first option, does this mean I would need to place all the nodes within the red square into an Execute Workflow node and then call this node during each iteration of the SplitInBatch loop?
For the second option, do you have an estimated time of arrival you can share?
Thanks,
Ludovic
Posted : 29/12/2021 3:09 pm
- Precisely. Ensure you incorporate a Set node within the sub-workflow to clear all data before returning. Failing to do so will result in data "leaking" back into the main workflow, bringing you back to square one.
- Unfortunately, there's no precise ETA, especially with the holidays approaching. Estimate 1-3 weeks.
Posted : 29/12/2021 3:22 pm
Topic starter
Thanks for the tips.
Unfortunately, even with these suggestions, it's not working. My mp3 files, even when downloaded individually and then processed, seem to exceed the maximum memory limit. So, I suppose I'll have to wait for the release.
What is the maximum file size that a workflow running on callin.io's start plan can currently handle? When conducting tests, my workflow functions with 600 KB mp3 files but fails with 1.4 MB mp3 files. So, I'm guessing the limit is somewhere in between?
When transitioning from RAM to hard drive storage, by how much will this capacity be increased?
Posted : 29/12/2021 7:34 pm
That's a bit tricky to answer definitively. It really depends on several factors, such as what other processes are running concurrently, the structure of your workflow, and whether it's being executed in a production environment or through the UI.
Generally, 1.4 MB shouldn't pose any issues, even on the most basic cloud plan. Could you double-check if your sub-workflow is returning any data, particularly binary data? That might be the cause.
Posted : 29/12/2021 8:18 pm
Topic starter
While conducting my tests, I removed the SplitInBatch loop and filtered for processing one file at a time to determine the file size at which it would begin to fail.
It's unusual that 1.4 MB isn't an issue, even on the most basic cloud plan.
Are there any storage best practices I should consider?
Posted : 29/12/2021 9:04 pm
No, nothing else besides what I've stated above.
I'm uncertain about the data volume in the remainder of the workflow, but all data accumulates. Therefore, you might consider reducing it and perhaps utilizing a sub-workflow to ensure only the necessary data resides in the main workflow. Additionally, it's important to consider what else is running within callin.io and make sure to disable "Save Execution Progress" as this can also consume RAM.
Posted : 29/12/2021 9:26 pm