Notifications
Clear all
Topic starter

This month, the callin.io team and community experts will be ready to answer YOUR questions about using callin.io & AI.
Our program will be:
- Introduction to AI in callin.io: We’ll explain how AI and LLMs can be integrated into workflows, highlighting their value in automation.
- Live Demos: Next, we’ll walk through 2-3 pre-prepared workflows, covering key steps and how each component (LLMs, connectors, nodes) is used.
- Q&A Segment: And finally, we’ll answer both pre-collected and live questions. For any question that needs an in-depth demo or explanation, please post it in a reply below!
Posted : 04/11/2024 2:23 pm
Looking forward to it!
![]()
Question:
How to make RAG reliable enough for production?
Background:
The primary challenge preventing us from moving from a POC to actually selling AI agents to companies is the unreliability of the secondary AI model that handles the actual vector database queries:
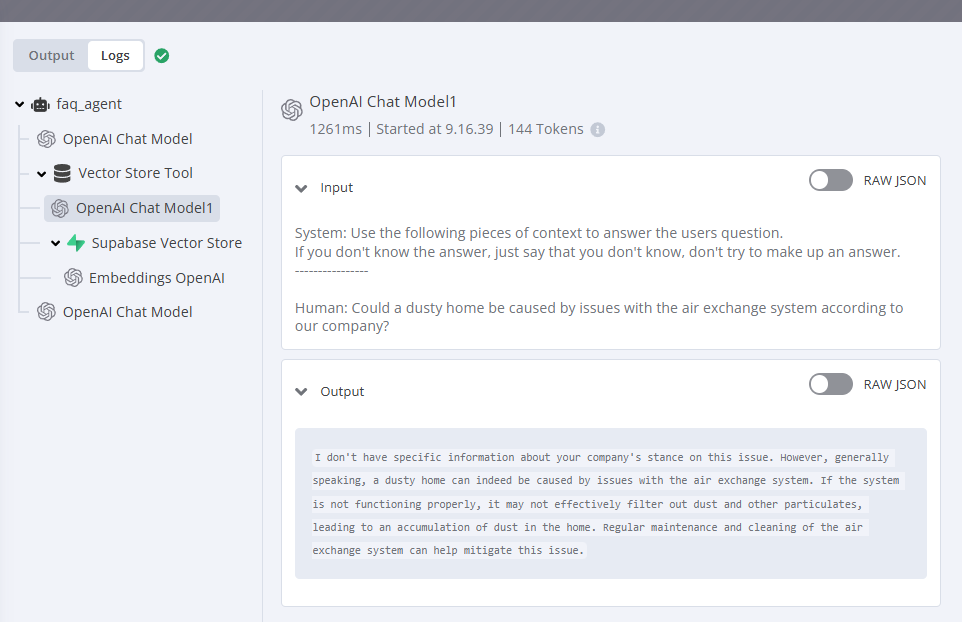
The issue:
Often it functions correctly, but when running hundreds of evaluations, instances arise where the secondary AI model suggests an answer from its training data. Sometimes it recommends contacting other companies in the vicinity, or it might suggest reaching out to customer service, etc.
When the secondary AI model provides a poor answer, the primary AI model accepts it as fact because it originates from the tool call.
What we have tried already:
- We are utilizing GPT-4o for both the primary AI agent and the secondary model.
- The sampling temperature is set to 0.1.
- We have experimented with adjusting the FAQ document format and included numerous examples demonstrating the correct way to indicate that an answer is unknown.
- We have prompted the primary FAQ agent to execute the tool call multiple times if no answer is found. However, a single erroneous response from the secondary model obstructs this process, as illustrated in the screenshot above.
- We have prompted the primary FAQ agent to format queries using a specific structure that further emphasizes our interest solely in answers from the vector database, but this has yielded limited success.
ps. If there's a method to control the prompt for the secondary AI agent that I've overlooked, please provide guidance, as that would largely resolve this issue.
Posted : 05/11/2024 7:44 am
Hello team
![]()
Here are some thoughts, which I'll update as more come to mind!
1. LLM Tracing Improvements
Are there plans to enhance the customizability of LLM tracing options within callin.io? As I understand it, the current tracing feature is based on Langsmith and configured at boot time via environment variables. Would it be possible to explore options for setting tracing, or perhaps BYO (Bring Your Own)? This could include the ability to set tracing per workflow, conditionally set them per execution, and add the capability to include extra metadata during an execution.
2. LLM & Agent Nodes: Support for Other Binary Types
As a proponent of multimodal LLMs, I'd appreciate an straightforward method to send audio, video, and even PDFs directly to LLMs without requiring conversion. Would you consider developing custom LLM nodes for major AI service providers to avoid limitations imposed by Langchain? For instance:
Explore document processing capabilities with the Gemini API | Google AI for Developers
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-1.5-flash:generateContent?key=$GOOGLE_API_KEY"
-H 'Content-Type: application/json'
-X POST
-d '{
"contents": [{
"parts":[
{"text": "Can you add a few more lines to this poem?"},
{"file_data":{"mime_type": "application/pdf", "file_uri": '$file_uri'}}]
}]
}'
Posted : 05/11/2024 11:44 am
Apologies, but I won't be able to make it. November 28th is Thanksgiving in the US, a time when families gather to watch NFL games and indulge in a lot of food! To add to that, it's also my wife's birthday! That just reminded me... I need to get her a gift.
![]()
Posted : 22/11/2024 1:52 pm
Is it possible to integrate OpenRouter.ai with Agents to facilitate easy selection of different AI models? OpenRouter functions effectively for workflows, but I'm encountering difficulties when attempting to use it with AI Agents.
Could someone provide guidance on this?
Posted : 22/11/2024 8:22 pm
Looking forward. A few questions from building a RAG pipeline:
- Using the AI Agent Node with a Structured Output Parser: does the LLM see the JSON schema and can thereby use it to answer the query with the right fields in the same way the LLM sees the JSON schema in the Information Extractor Node, or can it only call the structured output parser as a tool and get back a pass/fail?
- Is there a way to convert a PDF to images in callin.io cloud for use with multimodal RAG? The only method I could find is to go through an external API…
- Using a sub workflow execution as a tool to retrieve document chunks and provide context to the LLM in an AI Agent node, what output format should the sub workflow have: text or is a JSON object also possible/recommended? For example, a JSON holding the text chunk but also metadata, like page number, title, document name, etc.
- What is the best way to handle “Overloaded” (e.g. Claude Sonnet) and/or Token limit errors from an LLM in the AI Agent node? A custom error output loop with a wait node will run forever without some kind of retry counter. The built-in retry won’t work when the LLM outputs the error as “normal” text output, and also will retry on every failure which does not make sense for most errors.
Posted : 24/11/2024 10:21 am
Perhaps a simple question, but why is the sampling temperature set to 0.1 instead of 0 to prevent such hallucinations?
Posted : 24/11/2024 10:26 am
That's an excellent question!
![]()
- A low temperature (below 0.3) instructs the AI model to provide answers directly from the FAQ document.
- Higher temperatures (0.6+) enable the AI model to synthesize information from multiple sources to generate its response.
If we could manage the AI prompt for RAG, it would be possible to develop more sophisticated RAG agents capable of combining information from different sources, much like a human would. No single FAQ document can anticipate every possible question a customer service or sales representative might encounter. The ability to merge answers is crucial for creating new, comprehensive responses.
Posted : 27/11/2024 11:25 am
Regarding traceability, are you referring to evaluations?
We currently have to manually copy and paste from the logs to monitor evaluation rounds, which is quite a challenge.
![]()

Based on my understanding, we are expected to receive an evaluations feature early next year. This feature should help in tracking the AI's actions at each stage and scoring executions to gauge how prompt modifications impact the outcomes.
Posted : 27/11/2024 12:47 pm
Hello !
Is there a way to connect an open-source LLM capable of analyzing Document IDs (like ID Cards, Driver's Licenses, etc.)? The objective isn't to detect counterfeit IDs, but rather to extract data for populating other documents that we can retrieve.
Posted : 27/11/2024 12:58 pm
I prefer to utilize a vector database (qdrant) to enhance my assistant. The callin.io workflow should enable me to upload a file that the assistant can access. I enjoy collaborating with the AI to refine the data extracted from the file and subsequently store it as a reference in a vector database. Essentially, I aim to develop a tool for my colleagues to improve the assistant.
My question is: Which nodes would you suggest for allowing the user to provide a file and interact with the assistant?
Posted : 28/11/2024 11:11 am
Topic starter
I've just uploaded the recording from today's livestream. Hope you enjoy it!
Posted : 28/11/2024 6:17 pm
This was a very insightful and actionable episode - thanks to all contributors!
![]()
One question is on my mind. Besides all the practical gems in the vivid versioning-walkthrough from @oleg
![]()
, I am wondering, if the actual use cases couldn’t be catered by a conventional database via SQL. It felt a little bit like you had to do some additional pullups to get a vector database to behave like a relational database (with similarity search not being utilized or not even wanted). I would be interested, if I’m missing the point here.
![]()
Posted : 29/11/2024 8:33 am
Hello! Thanks a lot for this episode and most of all, for creating this awesome tool.
Is there any way to get the parsed output workflow .json you demonstrated on the video? That would be awesome!
Thanks a lot to all for all the information.
Posted : 29/11/2024 11:09 am
Hi all,
Was very instructive!
Few things I learned:
- forms with workflows between steps (never used this feature before but will be really helpful in my next project)
- execution is made left to right (seems natural) but also top to bottom : suddenly issues I had become crystal clear
 )
) - strategies to use AI, in particular the last example about having a node dedicated to output parsing instead of having it in agent (which sometimes loop multiple times just to have the correct format)
My sentiment: just have to test and learn what is the best for my use case!
Quick question for you: to extract data (from CVs or from the last example) I saw you did not use an information extractor node. Is there a reason to that (or are both node types interchangeable) ?
Can you update the link behind the initial post image so we found the replay easily? And I saw you added links to an example, if we can have the others too, that would be awesome!
Thanks everyone !
Posted : 02/12/2024 11:55 am
Page 1 / 2
Next