Notifications
Clear all
Topic starter
To boost the practicality and stability of Scraping Browser in cross-session scenarios, we've officially rolled out the Profile feature for persistent user data. This feature saves browser data (like cookies, storage, cache, and login states) to the cloud, allowing for seamless sharing and reuse across different sessions, thereby eliminating the need for repeated logins. It greatly simplifies debugging and enhances the efficiency of automation scripts.
Why Introduce Profiles?
In real automated capture or interaction processes, users often need to "remember login status", "reuse cookies from a particular crawl", and "synchronize page caches across tasks". Traditional headless browsers start in a completely new environment each time and cannot retain any historical context.
The new Profile feature addresses this by enabling Scraping Browser support for:
- Long-term retention of login status, removing the necessity to re-authenticate each time
- Consistent user identity across multiple requests to the same site
- Browser context reuse across sessions during script debugging
Highlights of this Update
Profile Creation and Management Page is Now Live
You can now navigate to "For Scraping → Profiles" to:
- Create/Edit/Copy/Delete
- View file data size, last used time
- Search for a target Profile by name or ID
- Copy IDs with a single click for scripting or team referencing.
Profile Detail Page: Full Visibility into Configuration and Usage History
Access any Profile to view its complete configuration and usage records, including:
- Basic Information: Profile name, ID, data size, last used time, and total usage count (i.e., how many times it has been used in Sessions);
-
Associated Session Records:
-
Live Session List: Real-time sessions currently utilizing this Profile;
-
Session History List: All historical sessions where this Profile was employed, with clickable entries for detailed viewing.
-
This enhances the transparency of the debugging process and aids in more efficient reproduction and tracing of issues.
Deep Integration with the Session System
We have also incorporated Profile information display and quick navigation within the following interfaces:
- Live Sessions: Displays the Profile currently in use (clickable to navigate to the Profile detail page)
- Session History: Shows the Profile associated with each session
- Session Detail: Allows you to see which Profile was utilized during a specific runtime.
Functional Demonstration
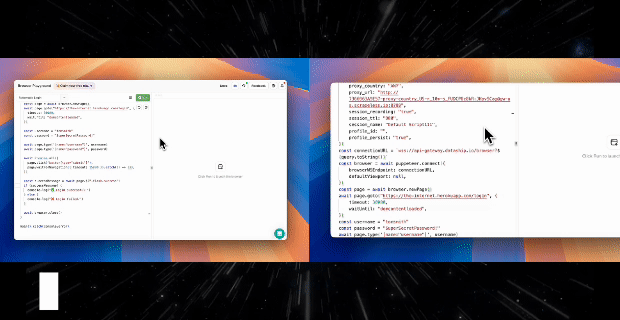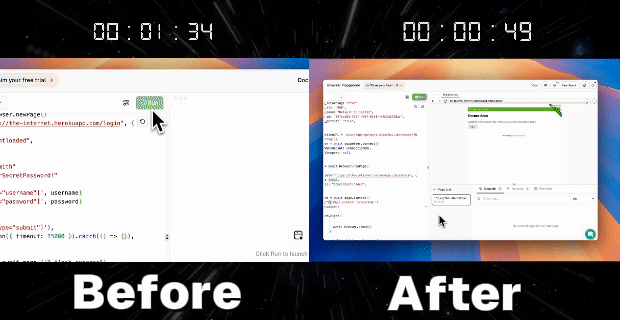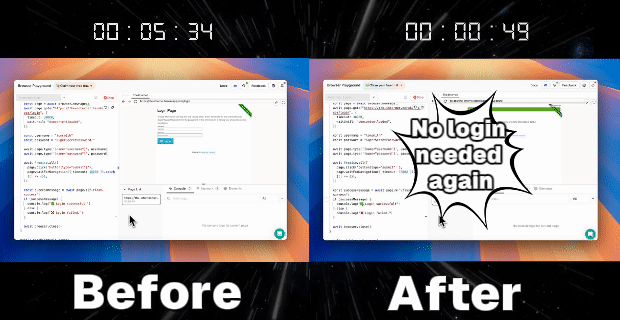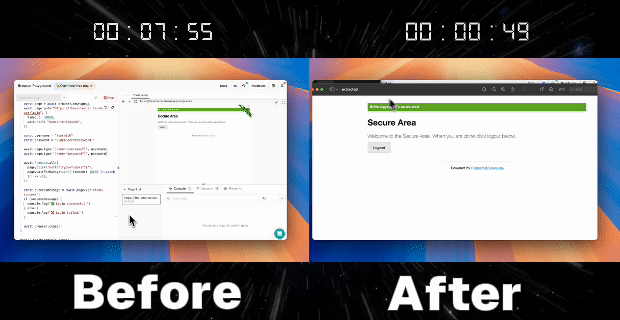
Case 1: Persistent Login + Improved Loading Speed
Goal: Automatically open pages that require login without needing to enter your username and password each time.
Steps:
1. Configure and save the login state for the initial use.
Ways to Create a Profile:
- Manual Creation via Dashboard: Set up Profiles manually through the Dashboard.
- API Creation: Automate Profile creation using the Create Profile API.
- SDK Creation: Generate Profiles using the SDK method.
NodeJS
import { Scrapeless } from "@scrapeless-ai/sdk"
const scrapeless = new Scrapeless({
apiKey: "YOUR_API_KEY"
})
// create a new profile
const profile = await scrapeless.profiles.create("scrapeless_profile")
console.log("profile Id:", profile.profileId)
Initiate a session, then specify the profile_id and enable persistence, and log in manually once. The login state (such as cookies and tokens) will be automatically stored in the cloud Profile.
NodeJS
import puppeteer from "puppeteer-core"
import { Scrapeless } from "@scrapeless-ai/sdk"
const scrapeless = new Scrapeless({
apiKey: "YOUR_API_KEY"
});
async function main() {
const proxy= "YOUR_PROXY"
const profileId = "YOUR_PROFILE_ID" // replace with your profileId
const { browserWSEndpoint } = scrapeless.browser.create({
proxy_country: "ANY",
proxy_url: proxy,
session_ttl: "900",
session_name: "Test Profile",
profile_id: profileId,
profile_persist: true,
});
const browser = await puppeteer.connect({
browserWSEndpoint,
defaultViewport: null,
})
const page = await browser.newPage()
await page.goto("https://the-internet.herokuapp.com/login", {
timeout: 30000,
waitUntil: "domcontentloaded",
})
const username = "your username"
const password = "your password!"
await page.type('[name="username"]', username)
await page.type('[name="password"]', password)
await Promise.all([
page.click('button[type="submit"]'),
page.waitForNavigation({ timeout: 15000 }).catch(() => { }),
])
const successMessage = await page.$(".flash.success")
if (successMessage) {
console.log("✅ Login successful!")
} else {
console.log("❌ Login failed.")
}
await browser.close()
}
main().catch(console.error)
2. Automatic Reuse of Login Information
- Utilize the same profileId in subsequent scripts or tasks
- Start a new session referencing the previously created profileId, automatically log in to https://the-internet.herokuapp.com/ and access the personal homepage
NodeJS
import puppeteer from "puppeteer-core"
import { Scrapeless } from "@scrapeless-ai/sdk"
const scrapeless = new Scrapeless({
apiKey: "YOUR_API_KEY"
});
async function main() {
const proxy= "YOUR_PROXY"
const profileId = "YOUR_PROFILE_ID" // replace with your profileId
const { browserWSEndpoint } = scrapeless.browser.create({
proxy_country: "ANY",
proxy_url: proxy,
session_ttl: "900",
session_name: "Test Profile",
profile_id: profileId,
profile_persist: true,
});
const browser = await puppeteer.connect({
browserWSEndpoint,
defaultViewport: null,
})
const page = await browser.newPage()
await page.goto("https://the-internet.herokuapp.com/secure", {
timeout: 30000,
waitUntil: "domcontentloaded",
})
const content = await page.content()
console.log("✅ Page content extracted.")
console.log(content)
await browser.close()
}
main().catch(console.error)
Case 2: Automatically Bypass Anti-Bot to Improve Automation Script Success Rate
Goal: In login processes involving anti-bot measures and CAPTCHAs, bypass CAPTCHAs through Profile persistence to minimize interruptions.
Test Site: https://www.leetchi.com/fr/login
Steps:
1. Pass CAPTCHAs and save the state
- Create a new Profile with browser persistence enabled
- Manually log in and complete the human CAPTCHAs (e.g., clicking a CAPTCHA, selecting images, etc.)
- All CAPTCHA results and login states will be saved to this Profile
NodeJS
import puppeteer from "puppeteer-core"
import { Scrapeless } from "@scrapeless-ai/sdk"
async function main() {
const token = "YOUR_TOKEN"
const proxy = "YOUR_PROXY"
const scrapeless = new Scrapeless({
apiKey: token
})
// create a new profile
const profile = await scrapeless.profiles.create("bot_profile")
// create browser session
const { browserWSEndpoint } = scrapeless.browser.create({
proxy_country: "ANY",
proxy_url: proxy,
session_recording: true,
session_ttl: 900,
session_name: "leetchi_profile",
profile_id: profile.profileId,
profile_persist: true,
})
const browser = await puppeteer.connect({
browserWSEndpoint: browserWSEndpoint,
})
const page = await browser.newPage()
await page.goto("https://www.leetchi.com/fr/login")
await addCaptchaListener(page)
await Promise.all([
page.waitForNavigation(),
page.click('button[data-testid="CookieModal-ConsentAccept-Button"]')
]);
await browser.close()
}
async function addCaptchaListener(page) {
return new Promise(async (resolve) => {
const client = await page.createCDPSession()
client.on("Captcha.detected", (msg) => {
console.log("Captcha.detected:", msg)
})
client.on("Captcha.solveFinished", async (msg) => {
console.log("Captcha.solveFinished:", msg)
resolve(msg)
client.removeAllListeners()
})
})
}
2. Reuse Verification Results for Automatic Login
- Initiate a new session in the script using the same profile_id
- The session will bypass CAPTCHAs and log in automatically without requiring any user interaction
NodeJS
import puppeteer from "puppeteer-core"
import { Scrapeless } from "@scrapeless-ai/sdk"
async function main() {
const token = "YOUR_API_EKY"
const proxy = "YOUR_PROXY"
const profileId = "YOUR_PROFILE_ID"
const scrapeless = new Scrapeless({
apiKey: token
})
const { browserWSEndpoint } = scrapeless.browser.create({
proxy_country: "ANY",
proxy_url: proxy,
session_recording: true,
session_ttl: 900,
session_name: "leetchi_profile_reuse",
profile_id: profileId,
profile_persist: false,
})
const browser = await puppeteer.connect({
browserWSEndpoint: browserWSEndpoint,
})
const page = await browser.newPage()
await page.goto("https://www.leetchi.com/fr/login")
await browser.close()
}
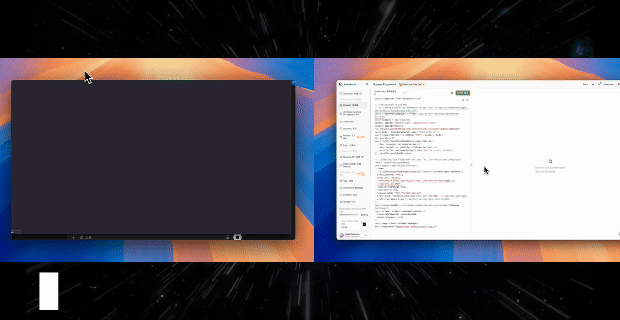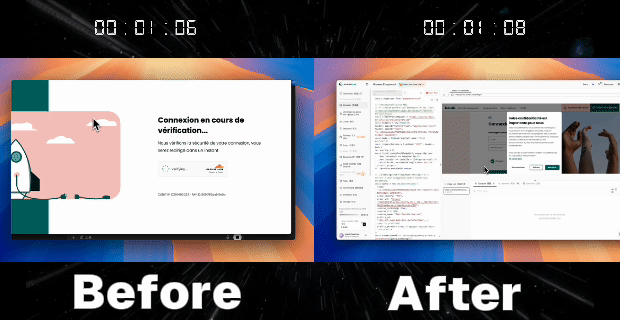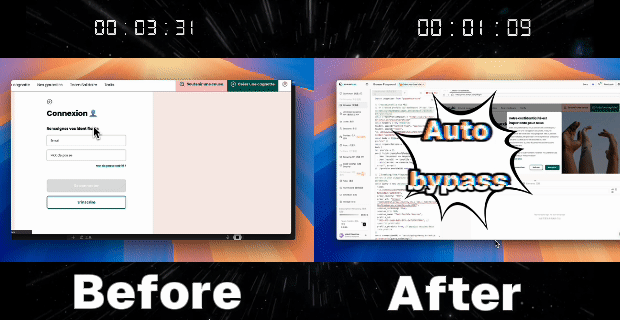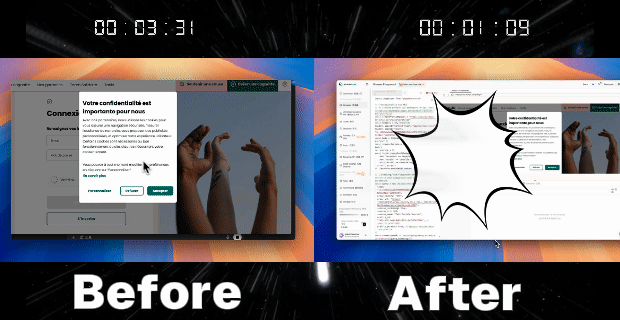
Case 3: Multi-Session Cookie Sharing
Goal: Multiple sessions share a single user identity to perform concurrent operations, such as adding items to a shopping cart.
Use Case: Manage multiple browsers to concurrently access platforms like Amazon and execute different tasks under the same account.
Steps:
1. Unified Identity Setup
- Create a shared Profile in the console
- Log in to Amazon by entering your username and password, then saving the session data after a successful login
NodeJS
import { Scrapeless } from "@scrapeless-ai/sdk"
import puppeteer from "puppeteer-core"
async function loginToAmazonWithSessionProfile() {
const token = "YOUR_API_KEY"; // API Key
const proxy = "YOUR_PROXY"
const amazonAccountEmail = "YOUR_EMAIL"
const amazonAccountPassword = "YOUR_PASSWORD"
const profileName = "amazon";
const scrapeless = new Scrapeless({ apiKey: token });
let profile;
let profileId = "";
// try to get existing profile, or create a new one
const profiles = await scrapeless.profiles.list({
name: profileName,
page: 1,
pageSize: 1,
});
if (profiles?.docs && profiles.docs.length > 0) {
profile = profiles.docs[0];
} else {
profile = await scrapeless.profiles.create(profileName);
}
profileId = profile?.profileId;
if (!profileId) {
return;
}
console.log(profile)
// Build connection URL for Scrapeless browser
const { browserWSEndpoint } = scrapeless.browser.create({
proxy_country: "ANY",
proxy_url: proxy,
session_recording: true,
session_ttl: 900,
session_name: "Login to amazon",
profile_id: profileId, // specific profileId
profile_persist: true, // persist browser data into profile
})
const browser = await puppeteer.connect({
browserWSEndpoint: browserWSEndpoint
})
const page = await browser.newPage();
await page.goto("https://amazon.com", { waitUntil: "networkidle2" });
// Click "Continue shopping" if present
try {
await page.waitForSelector("button.a-button-text", { timeout: 5000 });
await page.evaluate(() => {
const buttons = Array.from(document.querySelectorAll("button.a-button-text"));
const btn = buttons.find(b => b.textContent.trim() === "Continue shopping");
if (btn) btn.click();
});
console.log("clicked 'Continue shopping' button.");
} catch (e) {
console.log("'continue shopping' button not found, continue...");
}
// Click "Sign in" button
await page.waitForSelector("#nav-link-accountList", { timeout: 5000 });
await page.click("#nav-link-accountList");
console.log("clicked 'Sign in' button.");
// Enter email
await page.waitForSelector("#ap_email_login", { timeout: 5000 });
await page.type("#ap_email_login", amazonAccountEmail, { delay: Math.floor(Math.random() * 91) + 10 });
console.log("entered email.");
// Click "Continue"
await page.waitForSelector("#continue-announce", { timeout: 5000 });
await page.click("#continue-announce");
console.log("clicked 'Continue' button.");
// Enter password with random delay per character
await page.waitForSelector("#ap_password", { timeout: 5000 });
for (const char of amazonAccountPassword) {
await page.type("#ap_password", char, { delay: Math.floor(Math.random() * 91) + 10 });
}
console.log("entered password.");
// Click "Sign in" submit button
await page.waitForSelector("#signInSubmit", { timeout: 5000 });
await page.click("#signInSubmit");
console.log("clicked 'Sign in' submit button.");
Optionally: await page.waitForNavigation();
await browser.close();
}
(async () => {
await loginToAmazonWithSessionProfile();
})();
2. Concurrent Calls with Consistent Identity
-
Launch multiple sessions (e.g., 3), all referencing the same
profile_id -
All sessions operate under the same user identity
-
Execute different page actions independently, such as adding products A, B, and C to the shopping cart
-
Session 1 searches for
shoesand adds them to the cart
import { Scrapeless } from "@scrapeless-ai/sdk"
import puppeteer from "puppeteer-core"
async function addGoodsToCart() {
const token = "YOUR_API_KEY"
const proxy = "YOUR_PROXY"
const profileId = "YOUR_PROFILE_ID"
const search = "shoes"
const scrapeless = new Scrapeless({
apiKey: token
})
// create browser session
const { browserWSEndpoint } = scrapeless.browser.create({
proxy_country: "ANY",
proxy_url: proxy,
session_recording: true,
session_ttl: 900,
session_name: `goods ${search}`,
profile_id: profileId,
profile_persist: false, // disable session persist
})
const client = await puppeteer.connect({
browserWSEndpoint: browserWSEndpoint
})
const page = await client.newPage()
try {
await page.goto("https://www.amazon.com", { waitUntil: "networkidle2" })
await page.waitForSelector('input[id="twotabsearchtextbox"]', { timeout: 5000 })
// Search goods
console.log(`search goods: ${search}`);
await page.type('input[id="twotabsearchtextbox"]', search, { delay: Math.floor(Math.random() * 91) + 10 });
await page.keyboard.press('Enter');
await page.waitForSelector('button[id="a-autoid-3-announce"]', { timeout: 10000 })
// Click goods
await page.click('button[id="a-autoid-3-announce"]')
console.log(`clicked goods`);
await page.waitForSelector('div[id="a-popover-content-2"]', { timeout: 10000 })
await new Promise((resolve) => setTimeout(resolve, 5000))
const buttons = await page.$$('div#a-popover-content-2 button.a-button-text');
if (buttons.length > 0) {
// Click add to cart
await buttons[0].click();
console.log(`clicked add cart`);
}
await client.close();
} catch (e) {
console.log("Adding shopping cart failed.", e);
}
}
(async () => {
await addGoodsToCart()
})()
- Session 2 searches for
clothesand adds them to the cart
import { Scrapeless } from "@scrapeless-ai/sdk"
import puppeteer from "puppeteer-core"
async function addGoodsToCart() {
const token = "YOUR_API_KEY"
const proxy = "YOUR_PROXY"
const profileId = "YOUR_PROFILE_ID"
const search = "clothes"
const scrapeless = new Scrapeless({
apiKey: token
})
// create browser session
const { browserWSEndpoint } = scrapeless.browser.create({
proxy_country: "ANY",
proxy_url: proxy,
session_recording: true,
session_ttl: 900,
session_name: `goods ${search}`,
profile_id: profileId,
profile_persist: false, // disable session persist
})
const client = await puppeteer.connect({
browserWSEndpoint: browserWSEndpoint
})
const page = await client.newPage()
try {
await page.goto("https://www.amazon.com", { waitUntil: "networkidle2" })
await page.waitForSelector('input[id="twotabsearchtextbox"]', { timeout: 5000 })
// Search goods
console.log(`search goods: ${search}`);
await page.type('input[id="twotabsearchtextbox"]', search, { delay: Math.floor(Math.random() * 91) + 10 });
await page.keyboard.press('Enter');
await page.waitForSelector('button[id="a-autoid-3-announce"]', { timeout: 10000 })
// Click goods
await page.click('button[id="a-autoid-3-announce"]')
console.log(`clicked goods`);
await page.waitForSelector('div[id="a-popover-content-2"]', { timeout: 10000 })
await new Promise((resolve) => setTimeout(resolve, 5000))
const buttons = await page.$$('div#a-popover-content-2 button.a-button-text');
if (buttons.length > 0) {
// Click add to cart
await buttons[0].click();
console.log(`clicked add cart`);
}
await client.close();
} catch (e) {
console.log("Adding shopping cart failed.", e);
}
}
(async () => {
await addGoodsToCart()
})()
- Session 3 searches for
pantsand adds them to the cart
import { Scrapeless } from "@scrapeless-ai/sdk"
import puppeteer from "puppeteer-core"
async function addGoodsToCart() {
const token = "YOUR_API_KEY"
const proxy = "YOUR_PROXY"
const profileId = "YOUR_PROFILE_ID"
const search = "pants"
const scrapeless = new Scrapeless({
apiKey: token
})
// create browser session
const { browserWSEndpoint } = scrapeless.browser.create({
proxy_country: "ANY",
proxy_url: proxy,
session_recording: true,
session_ttl: 900,
session_name: `goods ${search}`,
profile_id: profileId,
profile_persist: false, // disable session persist
})
const client = await puppeteer.connect({
browserWSEndpoint: browserWSEndpoint
})
const page = await client.newPage()
try {
await page.goto("https://www.amazon.com", { waitUntil: "networkidle2" })
await page.waitForSelector('input[id="twotabsearchtextbox"]', { timeout: 5000 })
// Search goods
console.log(`search goods: ${search}`);
await page.type('input[id="twotabsearchtextbox"]', search, { delay: Math.floor(Math.random() * 91) + 10 });
await page.keyboard.press('Enter');
await page.waitForSelector('button[id="a-autoid-3-announce"]', { timeout: 10000 })
// Click goods
await page.click('button[id="a-autoid-3-announce"]')
console.log(`clicked goods`);
await page.waitForSelector('div[id="a-popover-content-2"]', { timeout: 10000 })
await new Promise((resolve) => setTimeout(resolve, 5000))
const buttons = await page.$$('div#a-popover-content-2 button.a-button-text');
if (buttons.length > 0) {
// Click add to cart
await buttons[0].click();
console.log(`clicked add cart`);
}
await client.close();
} catch (e) {
console.log("Adding shopping cart failed.", e);
}
}
(async () => {
await addGoodsToCart()
})()
Which Scenarios Are These Features Suitable For?
The introduction of Profiles significantly enhances Scraping Browser's performance in multi-user, multi-session, and complex workflow environments. Below are typical practical use cases:
Automated Data Collection / Crawling Projects
When frequently scraping websites that necessitate login (such as e-commerce, recruitment, or social media platforms):
- Maintain login states to prevent frequent risk control triggers;
- Preserve key contexts like cookies, storage, and tokens;
- Assign distinct identities (Profiles) for different tasks to manage account pools or identity pools.
Team Collaboration / Multi-Environment Configuration Management
Within development, testing, and operations teams:
- Each member maintains their own Profile configuration without interference;
- Profile IDs can be directly integrated into automation scripts to ensure consistent calls;
- Supports custom naming and bulk cleanup to maintain organized and clean environments.
QA / Customer Support / Online Issue Reproduction
- QA can pre-configure Profiles linked to key test cases, avoiding state reconstruction during playback;
- Customer support scenarios can restore users' operating environments via Profiles for accurate issue reproduction;
- All sessions can be linked to Profile usage records, aiding in the troubleshooting of context-related issues.
![]()
Open the Playground and experience it now.
Posted : 18/07/2025 9:04 am